Search Results for: ww sd vc
mal ne runde ssd’s getauscht…
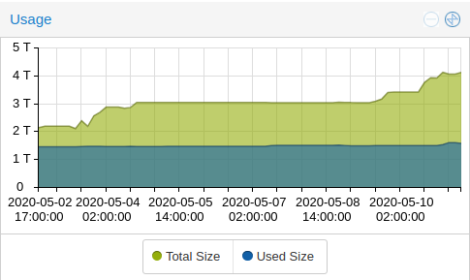
momentan laufen im “home rz” um die 35 VMs.. und der plattenplatz ging langsam zu neige. (ein ceph cluster darf man ja nie voll machen!)
also mal schlappe 15 stueck 1 tb ssds gekauft und die 500 gb dinger im laufenden betrieb eine nach der anderen ausgetauscht.
das reicht mir wieder ne ganze weile 🙂
proxmox: eine partition als osd nutzen
gleich vorneweg: nicht offiziell von proxmox unterstuetzt, aber (fuer mich) funktionieren tuts. 😉
fuer meine aktuelle “spielwiesen-evaluierung” habe ich als boot platte eine 500 GB ssd gekauft. da das betriebsystem und swap nur wenige gigabytes benoetigen, moechte den restlichen platz als OSD fuer ceph verwenden. proxmox unterstuetzt von haus aus nur kompletten festplatten als OSD. mit ein paar tricks kann man das aber trotzdem eintueten. dafuer muessen ein paar vorraussetzungen eingehalten und die folgenden schritte ausgefuehrt werden.
1. als grundlage habe ich ein debian stretch installiert. dabei waehlt man am besten den modus “expert install” aus, da man nur in diesem den typ der partition table der festplatte setzen kann. der installer macht standardmaessig eine MBR patrition table, aber wir brauchen zwingend eine des typs GPT!
2. das debian system samt proxmox und ceph installieren (siehe proxmox wiki)
3. danach muss die OSD partition wie folgt angelegt und praepariert werden:
als erstes setzen wir ein paar variablen… der partition typecode “is designating a Ceph data disk”
PTYPE_UUID=4fbd7e29-9d25-41b8-afd0-062c0ceff05d
die festplatte, die verwendet werden soll:
disk=/dev/sda
die nuemmer der partition ist die naechste freie nummer:
part=4
und eine zufaellige UUID wird benoetigt, um die neue OSD zu identifizieren:
(wenns nicht funktioniert, vorher noch das paket “uuid-runtime” installieren)
OSD_UUID=`uuidgen -r`
wenn all diese variablen gesetzt sind, kann mit dem sgdisk kommando die neue partition angelegt werden:
sgdisk --largest-new=$part --change-name="${part}:ceph" --partition-guid=${part}:$OSD_UUID --typecode=${part}:$PTYPE_UUID $disk
der output koennte so aussehen:
Setting name!
partNum is 3
REALLY setting name!
Warning: The kernel is still using the old partition table.
The new table will be used at the next reboot or after you
run partprobe(8) or kpartx(8)
The operation has completed successfully.
um die proxmox boardmittel nutzen zu koennen, muss man ein bischen in einem perl script rumpfuschen… und zwar das: /usr/share/perl5/PVE/API2/Ceph.pm
vorher bitte eine sicherungskopie anlegen, damit man die originale datei im anschluss wiederherstellen kann. (funktioniert mit pve 5.2)
suche in der datei nach diesem string:
$devname =~ s|/dev/||;
…und kommentiere diese und die folgenden zeilen bis zu dieser aus:
my $devpath = $diskinfo->{devpath};
dann fuege diese zeile darunter ein:
my $devpath = $devname;
jetzt suche nach
my $cmd = ['ceph-disk', 'prepare', '--zap-disk',
…und entferne am ende das argument “–zap-disk”, so dass die zeile so aussieht:
my $cmd = ['ceph-disk', 'prepare',
dann kann man endlich die OSD erstellen:
pveceph createosd /dev/sda4 --bluestore=0
(wenn die fehlermeldung “not a valid block device” kommt, ist noch ein reboot notwendig, damit der kernel die oben abgeaenderte partition table frisst.)
ich habe hier bluestore auf 0 gesetzt, da es bei mir nicht funktioniert hatte. (ich bin mir garnicht sicher, ob man bluestore ueberhaupt mit einer partition verwenden kann… vermutlich eher nicht.) so wird der herkoemmliche typ “filestore genommen und die partition mit xfs formatiert.
der output koennte so aussehen:
create OSD on /dev/sda4 (xfs)
meta-data=/dev/sda4 isize=2048 agcount=4, agsize=29150209 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0, rmapbt=0, reflink=0
data = bsize=4096 blocks=116600833, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=56934, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
und zum schluss noch die OSD aktivieren, wodurch die partition gemountet und der zugehoerige OSD daemon gestartet wird
ceph-disk activate /dev/sda4
und schon ist die partiton unter proxmox als OSD verfuegbar. in der proxmox oberflaeche wird die ganze festplatte als OSD angezeigt, was mich aber nicht weiter stoert 😉
.vc domains und dnssec
die antwort auf meine anfrage bzgl dnssec bei der zustaendigen registry fuer .vc domains kam fix:
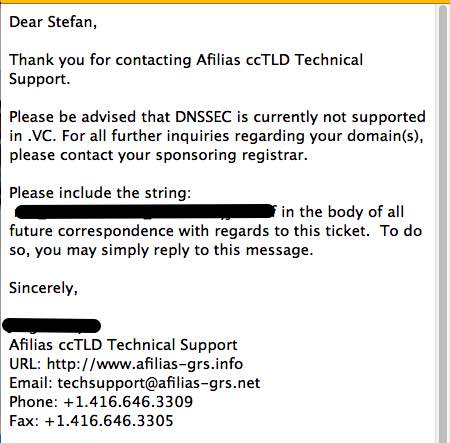
meine urspruengliche frage nach dem WANN blieb natuerlich unbeantwortet. und dann frei nach dem motto: belaestige uns doch nicht mit deiner “endkunden anfrage” und wende dich in zukunft an deinen registrar. naja, soll ich nun dankbar sein, dass ich wenigstens irgendeine antwort bekommen habe?
www.glgoo.com
gerade diesen referer in der piwikk statistik gefunden: www.glgoo.com
da muss man schon arg krumme finger haben, um sich so arg zu vertippen. und bei google landet man auch nicht, sondern bei irgendeinem chinesen.
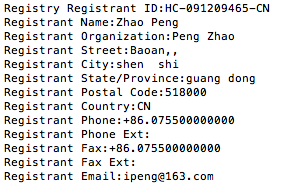
was wohl passiert, wenn man sich da einloggt? muss ich mir mal genauer ansehen 😉
diaspora server pod.sd.vc
mag denn jemand mit mir ein bischen rumtesten? bei diaspora is ja echt noch keine sau (die ich kenne). so alleine auf dem eigenen server hat zwar den mega vorteil, dass die kiste (im gegensatz zu den oeffentlichen) sauschnell ist, aber irgendwie fehlt halt was. vor allem die pod uebergreifenden geschichten wuerde ich gerne mal ausgiebbig testen. schliesslich ist ja einer der angepriesenen vorteile von diaspora die dezentrale struktur. wenn du, liebe/r blogleser/in bereits irgendwo einen diaspora account hast oder besser noch einen eigenen server betreibst, dann lass uns doch mal zusammen spielen. klar koennte ich mir auch selbst irgendwo accounts anlegen.. aber das ist doch doof.
ein kleines, um den faktor 37284 vereinfachtes schaubildchen hab ich gefunden:

die sache mit der dezentralen struktur hat folgenden… naja.. ich nenne es erstmal “haken”, der nach kurzem nachdenken natuerlich einleuchtend ist:
“Sollte die Person noch nie Bekanntschaft mit deinem Pod gemacht haben, also z. B. noch nie gesucht worden oder noch kein Kommentar von ihr eingegangen sein, so muss das Profil erst heruntergeladen werden. Das heißt, man kann nicht nach dem Namen der Person suchen sondern muss das sogenannte Diaspora-Handle benutzen (z.B. testperson@beispiel.com). Da diese Aufgabe zurzeit im Hintergrund bearbeitet wird, schlägt die erste Suche generell fehl. Nach kurzer Zeit sollte sie dann aber erfolgreich sein. Auch über den Namen sollte die Suche danach möglich sein, natürlich vorausgesetzt die Person ist suchbar, was im Profil deaktiviert werden kann.” (via)
pfsense + fon + drecksdesktop
was haben die sachen miteinander zu tun? erstmal nix. die bekommen nur mal aus reiner bequemlichkeit ein gemeinsames posting.
 die gute alte firebox mit pfsense hat mal ein lange ueberfaelliges update bekommen. von version 1.2.3 auf 2.0.. und das einfach per update funktion im webinterface. 5 minuten unbehagen waehrend des downloads und dann 30 sekunden angst, als die kiste gebootet hat. kommt sie wieder hoch? *schwitz* …ja! jetzt hab ich prima neue features, mit denen ich erstmal wieder rumspielen kann. aber irgendwie finde ich nichts offensichtliches mit “eipih vausex”… naja, erstmal die pfsense homepage durchstoebern. wenigstens kann ich nun “multiple pppoe connections” machen 😉
die gute alte firebox mit pfsense hat mal ein lange ueberfaelliges update bekommen. von version 1.2.3 auf 2.0.. und das einfach per update funktion im webinterface. 5 minuten unbehagen waehrend des downloads und dann 30 sekunden angst, als die kiste gebootet hat. kommt sie wieder hoch? *schwitz* …ja! jetzt hab ich prima neue features, mit denen ich erstmal wieder rumspielen kann. aber irgendwie finde ich nichts offensichtliches mit “eipih vausex”… naja, erstmal die pfsense homepage durchstoebern. wenigstens kann ich nun “multiple pppoe connections” machen 😉
 dann hab ich die tage beim rumraeumen im keller noch einen verpackten fonera+ 2.0 gefunden. zu schade zum rumliegen und ausserdem kann ich im keller auch gebrauchen. also hat die schachtel nen extra kabel in die firebox bekommen (hat ja schliesslich 6 ports), ein eigenes netz und ein paar passende firewall regeln, so dass der fonera nur ins internet kann und nicht ins interne netz. der fon router hat solche regeln schon selbst, aber wer will schon kleinen plastikgeraeten trauen, deren einstellungen man auf einer webseite im internet aendern kann? wer fon nicht kennt, kann ja mal die webseite besuchen.
dann hab ich die tage beim rumraeumen im keller noch einen verpackten fonera+ 2.0 gefunden. zu schade zum rumliegen und ausserdem kann ich im keller auch gebrauchen. also hat die schachtel nen extra kabel in die firebox bekommen (hat ja schliesslich 6 ports), ein eigenes netz und ein paar passende firewall regeln, so dass der fonera nur ins internet kann und nicht ins interne netz. der fon router hat solche regeln schon selbst, aber wer will schon kleinen plastikgeraeten trauen, deren einstellungen man auf einer webseite im internet aendern kann? wer fon nicht kennt, kann ja mal die webseite besuchen.
 und der drecksdesktop? auf zdnet bin ich ueber eine lustige schlagzeile gestolpert: “Unklare Strategie: Ruiniert Microsoft gerade Windows?”
und der drecksdesktop? auf zdnet bin ich ueber eine lustige schlagzeile gestolpert: “Unklare Strategie: Ruiniert Microsoft gerade Windows?”
da steht geschrieben: “Mit der Metro-style-Oberfläche – optisch an Windows Phone 7 angelehnt – bekommt Windows endlich ein Interface, das ohne Einschränkung für die Fingerbedienung geeignet ist. […] In Redmond hat man sich nämlich in den Kopf gesetzt das Interface, von dem jeder dachte, es sei nur für Tablets konzipiert, zur Standardoberfläche von Windows zu machen. Im Klartext: Anstatt Startmenü und Desktop sind künftig Live Tiles und Vollbild-Metro-style-Apps angesagt.” na herzlichen glueckwunsch… nach ubuntu (mit unity) kriegt windows jetzt auch noch eine unbenutzbare desktopoberflaeche. sicher kann man das alles wieder umstellen auf was brauchbares… ich frag mich nur, warum man mit aller gewalt alles bewaehrte “kaputt” machen will und den endbenutzern “innovationen” aufdrueckt, die sie garnicht haben wollen.
sd.vc ist jetzt ueber https erreichbar
dieses blog ist nun auch ueber https, ssl, port 443, whatever erreichbar. inspiriert durch das (absolut falsche und indiskutable) bauernmotto “ich hab ja nix zu verbergen” hier nun meine (gegen-)aktion “und es geht trotzdem niemanden was an”. verschluesselte kommunikation ist gut.
im moment ist auch noch die unverschluesselte kommunikation moeglich. ich bin mir noch nicht sicher, ob ich irgendwann auf ssl-only umstelle. es gibt verschiedene gruende dafuer und dagegen. (rein technischer natuer uebrigens)
![]() der vollstaendigkeit halber hier noch der sha1 fingerprint des verwendeten zertifikats (von cacert):
der vollstaendigkeit halber hier noch der sha1 fingerprint des verwendeten zertifikats (von cacert):
29:1C:0C:A9:A6:66:B1:18:73:E9:5D:EA:33:A4:70:E1:C0:22:02:19
und bevor hier kommentare kommen wie “ich bekomme ne fehlermeldung angezeigt… bla… “, sei auf das cacert wiki verwiesen.
aol.de ohne www
wieviel hundert jahre lang muss eine firma existieren, bis sie lernt, wie man das richtig macht?

oder:
# nslookup aol.de
[…]
*** Can’t find aol.de: No answer
wann wird aol eigentlich abgeschaltet?
windows storage replication – error code: 0x80131500, native error code: 6
ich will es mal hier festhalten, da man sonst beim googlen niemals auf die ursache kommt. der fehler kommt am ende des einrichtungswizard bei der storage replication in einem windows cluster:
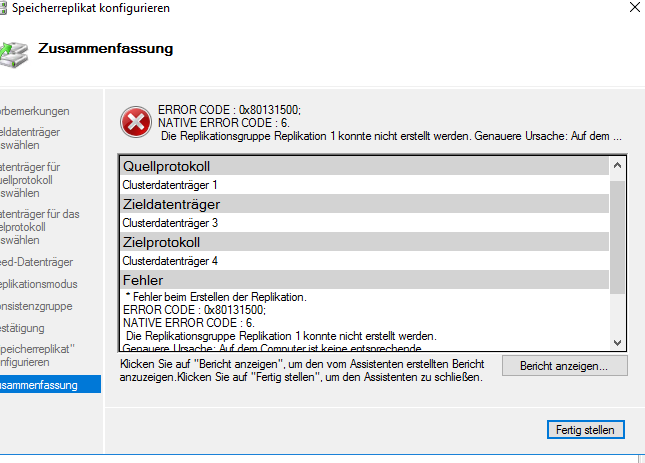
bei den “Known issues with Storage Replica” ists leider auch nicht aufgefuehrt. leider habe ich den rest der fehlermeldung nicht mehr parat. das war auf die art “kann partition mit der guid bla nicht finden”
die ursache ist ein per GPO deaktivierter service namens “Microsoft Storage Spaces SMP” oder auf deutsch “Microsoft-SMP für Speicherplätze” bzw in der kurzform “smphost”. drauf gekommen bin ich, als ich bei der diagnose einige powershell kommandos ausprobiert habe und z.b. bei dem befehl “Get-Disk” nichts zurück kam. Die Ursache konnte man dann ergooglen. dienst auf manuell stellen und schon klappts ….
mal sehen, wie es mit der stabilitaet so ist…
ich hatte mich gefreut wie lumpi, aber irgendwie traute ich der sache von anfang an nicht. deswegen schrieb ich als letzten satz ja auch “mal sehen, wie es mit der stabilitaet so ist…”
tja… was soll ich sagen. der ruf eilt unitymedia bzw vodafone ja voraus… ich fange mal an….
meine opnsense macht ja bei den wan verbindungen sogenanntes gateway monitoring. dieses pingt einfach nur eine definitierte ipadresse an um festzustellen, ob die leitung funktioniert um im bedarfsfall dann automatisch auf die andere leitung umzuschalten. die meiste zeit schaut das so aus:
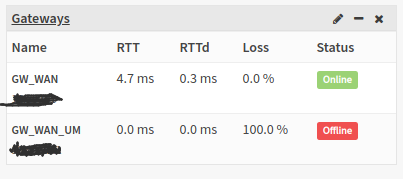
das interessante ist, dass der anschluss ja eigentlich so halb funktioniert. laeppische ping pakete sind aber zuviel fuer den gigabit anschluss. “ping? wozu? technik aus dem letzten jahrtausend! hauptsache gigabit! bla, duennschissgelaber” … wenn man zum thema packetloss + um/vf onkel google fragt, wird man von den ergebnissen erschlagen. also mal weiter schauen… z.b. in der fritzbox. auf der seite mit “kabel informationen” siehts exemplarisch so aus:

die fritzbox hat in der gui eine feste spaltenbreite, kuerzt die zahlenwerte und stellt sie mit “…” dar. werte im einstellige millionenbereich passen in die spalte, danach wird gekuerzt. interessant hier ist der kanal 7 und die nicht korrigierbaren fehler auf der leitung. diese sind zwei minuten nach einem reboot der fritzbox schon im 2stelligen millionbereich. (ohne, dass die leitung ueberhaupt von mir genutzt wird.) gerade eben erst gesehen habe ich einen punkt als trennzeichen (rot markiert im screenshot). also mal flux die “supportdaten” der fritzbox in textform generiert und da rein geschaut. der punkt bedeutet also, dass der wert im bereich der milliarden ist. puuu… wieder onkel google gefragt und von ergebnissen erschlagen worden.
mach ich halt mal ne stoerung auf. da es sich um enen business anschluss handelt, kam auch recht zuegig jemand vorbei. der wollte nach kurzer messung an der dose dann mal zum hausanschluss. und da klemmts jetzt… es gibt einen anschluss in dem 20 parteien wohnobjekt. der ist leider im keller einer sehr alten dame und der zugang gestaltet sich etwas schwierig. unverrichteter dinge ist der techniker ertmal von dannen gezogen.
ich muss ehrlicherweise erwaehnen, dass die verkabelung in diesem wohnobjekt sehr abenteuerlich ist. von dem zentralen anschluss gehen kabel mit T-abzweigern von keller zu keller und von da jeweils nach oben in die wohnungen und wird da sicherlich noch irgendwie verzweigt. quasi multi-bus-stern-misch-topologie. kann man so machen – ist dann halt kacke. mein anschluss ist natuerlich ganz am ende der kette und man kann sich denken, dass da nur noch muell raus kommt. wenn jemand in seiner wohnung an den dosen rumbastelt, passt natuerlich die komplette einpegelung der verteilung nicht mehr. dazu kann vodafone nun erstmal nix. aber wenn man sein produkt halt auf so nen murks aufbaut, dann… naja lassen wir das.
also muss ein neuer termin her. der beauftragte subunternehmer von vodafone wollte von sich aus einen neuen termin mit mir vereinbaren. dazu benutzen die so nen anrufroboter, der die kunden anruft und sagt “blabla.. bitte warten sie. sie werden automatisch mit dem naechsten freien mitarbeiter verbunden”. nur bloed, dass mir dieser roboter auf meine mailbox gequatscht hat und ein gespraech mit mir nicht stattgefunden hat.
ich koennte hier immer so weiter schreiben. die geschichte hat noch mehr komische stilblueten getrieben und wird auch noch weiter gehen. aber dazu muesster ich mir ein paar tage urlaub nehmen. mir war aus eigener erfahrung mit diesem provider und horrorgeschichten anderer schon vorher klar, dass ich von diesem anschluss nicht zu viel erwarten darf. da es sich “nur” um den backup anschluss handelt, ists ja auch nicht sooo tragisch. allerdings sollte der schon irgendwann mal funktionieren… fuer den fall, dass ich ihn tatsaechlich mal brauche.
und da es gerade zum thema passt… noch ein bildchen aus facebook.

so wird mit den kunden umgegangen. die hotline wurde zeitweise wegen ueberlastung aufgrund zu vieler stoeriungen abgeschaltet. aber hey.. man kanns ja immernoch positiv als “24h service” verkaufen, wenn man so bildchen bei facebook postet. und was solls. nen werksreset macht doch jeder kunde gern und oft. wozu also erst die hotline damit nerven, dass der scheiss nicht funktioniert? (ich selbst mache das lustigerweise meistens, bevor ich irgendeine hotline anrufe. neu starten und ggf. werkseinstellungen. davon erhoffe ich mir so schnell wie moeglich an der first level firewall in der hotline vorbei zu kommen. manchmal klappts, manchmal nicht).
