in einem proxmox/ceph cluster mit insgesamt sieben nodes sind vier identische nodes nur für den ceph storage zustaendig. alles supermicro x8dtl-3f mit ssds und 10gbit nics.
irgendwann… ich weiss nicht genau wann… aber auf jeden fall nach dem update auf debian stretch und pve5 hatten diese vier server problemchen. erstmal sah es so aus, als ob es mehrere verschiedene probleme sind.
1. in einem zeitraum von 1 bis 7 tage booteten die server spontan und ohne erkenntlichen grund. keine eintraege im syslog und nichts im bios/ipmi eventlog zu sehen.
2. weniger haeufig kam es vor, dass ein node zwar noch “online” war, aber alle seine festplatten “verloren” hat. seh dann auf dem bildshirm so aus:
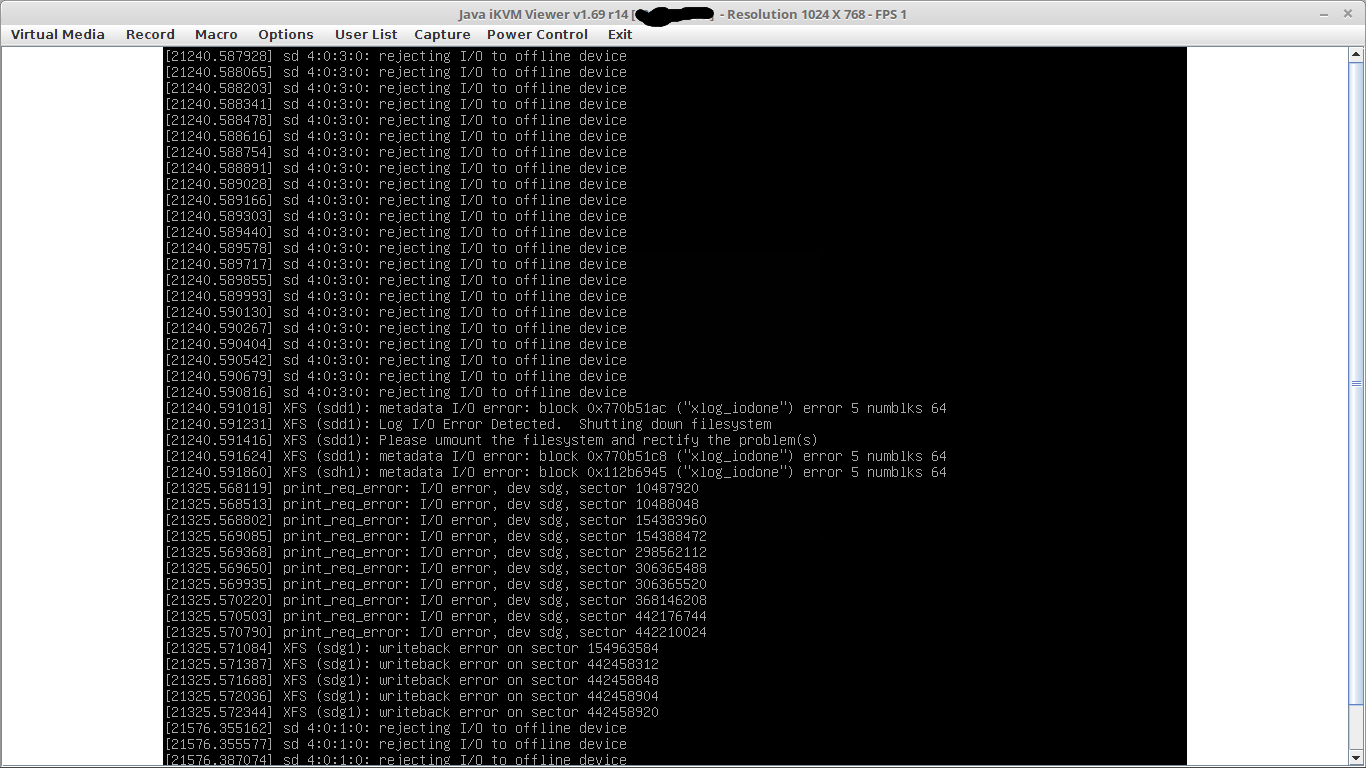
3. die onboard netzwerkkarten haben rumgezickt, was im logfile dann so aussah:

das hat sich dann im sekundentakt wiederholt
4. selten bekam ich meldungen wie diese auf den schirm:
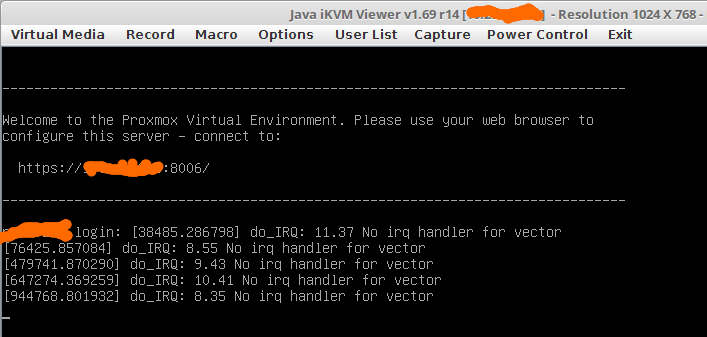
wie sich aber rausstellte, war das genau das ausschlaggebende! falls noch was im syslog zu sehen war (eher garnicht ausser bei dem nic flapping), dann war auch immer so eine meldung unmittelbar davor zu sehen.
nach ein wenig googlen kam heraus, dass der “irqbalanced” fuer diese meldungen verantwortlich ist. der irqbalanced kann im laufenden betrieb irq’s bei bedarf auf eine andere cpu mappen. wenn man google nach diesem ding fragt, bekommt man viele aussagen. von “braucht man nicht, weil aktuelle kernels das von alleine koennen” bis “sehr wichtig bei hoher last fuer performanceoptimierungen”.
ich hab dann kurzerhand in der datei /etc/default/irqbalance den parameter “IRQBALANCE_ONESHOT=YES” gesetzt. in der beschreibung dazu steht: “after starting, wait for a minute, then look at the interrupt load and balance it once; after balancing exit and do not change it again.”
….und was soll ich sagen. seit vier wochen habe ich nun ruhe und die server lauifen durch 🙂
fuer eine genaua analyse und warum das seit wann auftritt… puh.. da fehlt mir die zeit. ich hab mich lange genug damit beschaeftigt und nun laufen die kisten wieder rund.
