Tag: linux
list ciphers supported by an http server
nmap --script ssl-enum-ciphers -p 443 www.example.com
…und natuerlich geht das nicht nur fuer http, sondern jede ssl verbindung.
bitwarden docker is eating disk
nach ner weile sammelt sich hier unbenutzter kram: /var/lib/docker/overlay2
so wird man den los:
docker system prune --all --volumes --force
rpcbind lauscht auf 111 – abschalten
systemctl stop rpcbind
systemctl disable rpcbind
systemctl mask rpcbind
systemctl stop rpcbind.socket
systemctl disable rpcbind.socket
check mit:
netstat -ntupl | grep 111
no matching key exchange method found
nach update eines “jumphosts” scheiterte die verbindung zu einer leider noch vorhandenen urlat linux kiste mit folgender fehlermeldung:
Unable to negotiate with 10.x.x.x port 22: no matching key exchange method found. Their offer: diffie-hellman-group-exchange-sha1,diffie-hellman-group14-sha1,diffie-hellman-group1-sha1
damit die verbindung doch noch irgendwie klappt ist eine moeglichkeit fuer diesen host “ausnahmen” zu definieren. dazu einfach eine datei “/etc/ssh/ssh_config.d/hostname.conf” anlegen mit folgendem inhalt
Host hostname
KexAlgorithms +diffie-hellman-group1-sha1
Ciphers +aes128-cbc
Host xxx.xxx.xxx.xxx
KexAlgorithms +diffie-hellman-group1-sha1
Ciphers +aes128-cbc
opnsense festplatte vergroessern
ohne grosse worte…
root@f1:~ # gpart show /dev/da0
=> 40 27262896 da0 GPT (13G)
40 409600 1 efi (200M)
409640 1024 2 freebsd-boot (512K)
410664 14680056 3 freebsd-ufs (7.0G)
15090720 12172216 - free - (5.8G)
root@f1:~ # gpart resize -i 3 da0
da0p3 resized
root@f1:~ # gpart show /dev/da0
=> 40 27262896 da0 GPT (13G)
40 409600 1 efi (200M)
409640 1024 2 freebsd-boot (512K)
410664 26852272 3 freebsd-ufs (13G)
root@f1:~ # df -h
Filesystem Size Used Avail Capacity Mounted on
/dev/gpt/rootfs 6.8G 5.2G 1.0G 83% /
devfs 1.0K 1.0K 0B 100% /dev
devfs 1.0K 1.0K 0B 100% /var/dhcpd/dev
root@f1:~ # growfs /dev/gpt/rootfs
Device is mounted read-write; resizing will result in temporary write suspension for /.
It's strongly recommended to make a backup before growing the file system.
OK to grow filesystem on /dev/gpt/rootfs, mounted on /, from 7.0GB to 13GB? [yes/no] yes
super-block backups (for fsck_ffs -b #) at:
15387072, 16669312, 17951552, 19233792, 20516032, 21798272, 23080512, 24362752, 25644992
root@f1:~ # df -h
Filesystem Size Used Avail Capacity Mounted on
/dev/gpt/rootfs 12G 5.2G 6.2G 45% /
devfs 1.0K 1.0K 0B 100% /dev
devfs 1.0K 1.0K 0B 100% /var/dhcpd/dev
dovecot maildir subscriptions file erstellen
“irgendwie” kam mir im dovecot maildir meine subscriptions datei abhanden 😉
und bevor ich meine maus kaputt mache, wenn ich 1384347 unterordner einzeln anklicken muss… dann lieber per script im maildir verzeichnis:
find . -maxdepth 1 -type d | grep --color=NEVER "\./\." | sed -e 's|\./\.||g' > subscriptions
endlich pxe ;-)
wollte ich schon immer mal haben… die letzten tage hab ich dann immer mal wieder etwas gebastelt. nun kann im heimnetzwerk von pxe gebootet werden.
diverse rettungssysteme und so zeugs, was man halt braucht werden direkt uebers netz vom nas gebootet. wenn man das noch nie gemacht hat, war das teilweise echt frickelig. aber wenns dann erstmal klappt…
anleitungen dazu werde ich vermutlich nicht machen. hab da ein paar gute gefunden.
einen raspi4 hab ich auch schon dazu gebracht via pxe zu booten. das gefrickel mit den speicherkarten hat mich genervt. ausserdem gehen die irgendwann kaputt. der raspi wird ein thinclient fuers homeoffice 😉
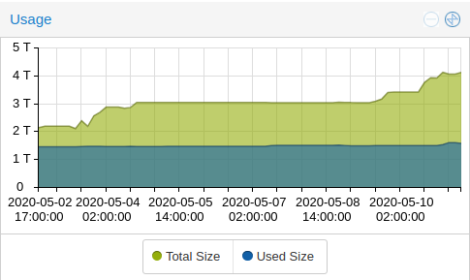
mal ne runde ssd’s getauscht…
momentan laufen im “home rz” um die 35 VMs.. und der plattenplatz ging langsam zu neige. (ein ceph cluster darf man ja nie voll machen!)
also mal schlappe 15 stueck 1 tb ssds gekauft und die 500 gb dinger im laufenden betrieb eine nach der anderen ausgetauscht.
das reicht mir wieder ne ganze weile 🙂
fritzbox reboot mit cronjob
seit super vectoring spinnt meine fritzbox 7590 alle paar wochen mal rum. dann hat das entertain tv aussetzer und laeuter so spaesschen. also ein kleines scriptchen auf einen der linux server drauf, welches die fritzbox regelmaessig neu starten soll. auf der fritzbox extra einen user “reboot” dafuer angelegt und ihm die Berechtigung “FRITZ!Box Einstellungen” gegeben, den port 49000 zur fritzbox in der firewall freigeschaltet und einen woechentlichen cronjob dafuer angelegt. und hier das script:
#!/bin/bash
IP="10.10.10.1"
FRITZUSER="reboot"
FRITZPW="strongpassword"
location="/upnp/control/deviceconfig"
uri="urn:dslforum-org:service:DeviceConfig:1"
action='Reboot'
curl -k -m 5 --anyauth -u "$FRITZUSER:$FRITZPW" http://$IP:49000$location -H 'Content-Type: text/xml; charset="utf-8"' -H "SoapAction:$uri#$action" -d "
(nicht selbst erfunden, sondern irgendwo abgeschaut. finde bloss nicht mehr wo…)
perl: warning setting locale failed unter debian
nach dem letzten update meines arbeitsplatz rechners mit linux mint, bekomme ich bei ssh verbindungen zu diversen servern bei perl basierten anwendungen meist sowas:
perl: warning: Setting locale failed.
perl: warning: Please check that your locale settings:
LANGUAGE = "en_US:en",
LC_ALL = (unset),
LC_MEASUREMENT = "de_DE.UTF-8",
LC_PAPER = "de_DE.UTF-8",
LC_MONETARY = "de_DE.UTF-8",
LC_NAME = "de_DE.UTF-8",
LC_ADDRESS = "de_DE.UTF-8",
LC_NUMERIC = "de_DE.UTF-8",
LC_TELEPHONE = "de_DE.UTF-8",
LC_IDENTIFICATION = "de_DE.UTF-8",
LANG = "en_US.UTF-8"
are supported and installed on your system.
perl: warning: Falling back to a fallback locale ("en_US.UTF-8").
locale: Cannot set LC_ALL to default locale: No such file or directory
/usr/bin/locale: Cannot set LC_ALL to default locale: No such file or directory
da das problem nur bei ssh verbindungen auftritt, sollte beim ssh client die option SendEnv LANG LC_* in der datei /etc/ssh/ssh_config deaktiviert (auskommentiert) werden
