Tag: software
endlich pxe ;-)
wollte ich schon immer mal haben… die letzten tage hab ich dann immer mal wieder etwas gebastelt. nun kann im heimnetzwerk von pxe gebootet werden.
diverse rettungssysteme und so zeugs, was man halt braucht werden direkt uebers netz vom nas gebootet. wenn man das noch nie gemacht hat, war das teilweise echt frickelig. aber wenns dann erstmal klappt…
anleitungen dazu werde ich vermutlich nicht machen. hab da ein paar gute gefunden.
einen raspi4 hab ich auch schon dazu gebracht via pxe zu booten. das gefrickel mit den speicherkarten hat mich genervt. ausserdem gehen die irgendwann kaputt. der raspi wird ein thinclient fuers homeoffice 😉
mal ne runde ssd’s getauscht…
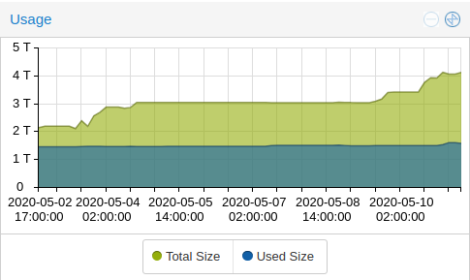
momentan laufen im “home rz” um die 35 VMs.. und der plattenplatz ging langsam zu neige. (ein ceph cluster darf man ja nie voll machen!)
also mal schlappe 15 stueck 1 tb ssds gekauft und die 500 gb dinger im laufenden betrieb eine nach der anderen ausgetauscht.
das reicht mir wieder ne ganze weile 🙂
oracle client (dynamisch + silent) deinstallieren
wer einen oracle client mal automatisch deinstallieren musste, der wird erstmal suchen muessen, wie das unbeaufsichtigt funktioniert. damit man keine statischen antwortdateien bei der deinstallation verwenden muss, werden die zur laufzeit erzeugt. das ist nicht auf meinem mist gewachsen, sondern > hier < abgeguckt und angepasst.
# Read Oracle Home from registry
$OraHome = (Get-ItemProperty “HKLM:\SOFTWARE\ORACLE\KEY_OraClient12Home1”).ORACLE_HOME
# Remove old rsp files in temp folder
Get-ChildItem -Path “$env:Temp” -Filter “deinstall_OraClient12Home1.rsp” -Recurse -Depth 2 | Remove-Item
# Generate new deinstall rsp file via “-checkonly”
& “$OraHome\deinstall\deinstall.bat” -silent -checkonly
# Get the new rsp file in temp folder
$RspFile = Get-ChildItem -Path “$env:Temp” -Filter “deinstall_OraClient12Home1.rsp” -Recurse -Depth 2
# Deinstall via rsp file
& “$OraHome\deinstall\deinstall.bat” -silent -paramfile `”$($RspFile.FullName)`”
# Remove leftover files
Remove-Item $OraHome -force -Recurse
behauptung fehlgeschlagen
eine passende fehlermeldung bei den bestell terminals im mcdonalds. von wegen irgendwas “geniessen” im mcdonalds… und dann die fehlermeldung von der software “assertion failed”, was woertlich uebersetzt “behauptung fehlgeschlagen” bedeutet. 😉
selbst wenn jemand den frass gerne isst… mal hand aufs herz… “geniessen” ist keines der woerter, die ich mit irgendwas in bezug auf mcdonalds in verbindung bringen wuerde.

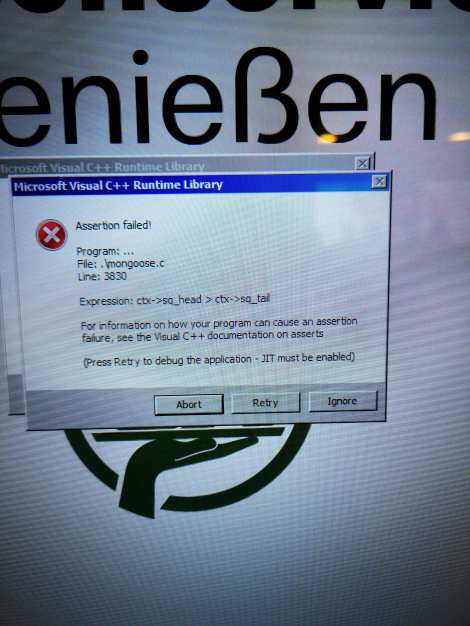
lasst uns lieber mal darueber spekulieren, warum eine datei aus dem programm “mongoose.c” heisst. was haben diese tierchen mit mcdonalds zu tun? 😉
fritzbox reboot mit cronjob
seit super vectoring spinnt meine fritzbox 7590 alle paar wochen mal rum. dann hat das entertain tv aussetzer und laeuter so spaesschen. also ein kleines scriptchen auf einen der linux server drauf, welches die fritzbox regelmaessig neu starten soll. auf der fritzbox extra einen user “reboot” dafuer angelegt und ihm die Berechtigung “FRITZ!Box Einstellungen” gegeben, den port 49000 zur fritzbox in der firewall freigeschaltet und einen woechentlichen cronjob dafuer angelegt. und hier das script:
#!/bin/bash
IP="10.10.10.1"
FRITZUSER="reboot"
FRITZPW="strongpassword"
location="/upnp/control/deviceconfig"
uri="urn:dslforum-org:service:DeviceConfig:1"
action='Reboot'
curl -k -m 5 --anyauth -u "$FRITZUSER:$FRITZPW" http://$IP:49000$location -H 'Content-Type: text/xml; charset="utf-8"' -H "SoapAction:$uri#$action" -d "
(nicht selbst erfunden, sondern irgendwo abgeschaut. finde bloss nicht mehr wo…)
perl: warning setting locale failed unter debian
nach dem letzten update meines arbeitsplatz rechners mit linux mint, bekomme ich bei ssh verbindungen zu diversen servern bei perl basierten anwendungen meist sowas:
perl: warning: Setting locale failed.
perl: warning: Please check that your locale settings:
LANGUAGE = "en_US:en",
LC_ALL = (unset),
LC_MEASUREMENT = "de_DE.UTF-8",
LC_PAPER = "de_DE.UTF-8",
LC_MONETARY = "de_DE.UTF-8",
LC_NAME = "de_DE.UTF-8",
LC_ADDRESS = "de_DE.UTF-8",
LC_NUMERIC = "de_DE.UTF-8",
LC_TELEPHONE = "de_DE.UTF-8",
LC_IDENTIFICATION = "de_DE.UTF-8",
LANG = "en_US.UTF-8"
are supported and installed on your system.
perl: warning: Falling back to a fallback locale ("en_US.UTF-8").
locale: Cannot set LC_ALL to default locale: No such file or directory
/usr/bin/locale: Cannot set LC_ALL to default locale: No such file or directory
da das problem nur bei ssh verbindungen auftritt, sollte beim ssh client die option SendEnv LANG LC_* in der datei /etc/ssh/ssh_config deaktiviert (auskommentiert) werden
ceph und festplattencontroller
man muss ja selbst seine erfahrungen machen mit ceph & co…. die leute von proxmox schreiben in ihren forumsbeitraegen auch immer, dass man seine hardware vor dem betrieb testen soll.
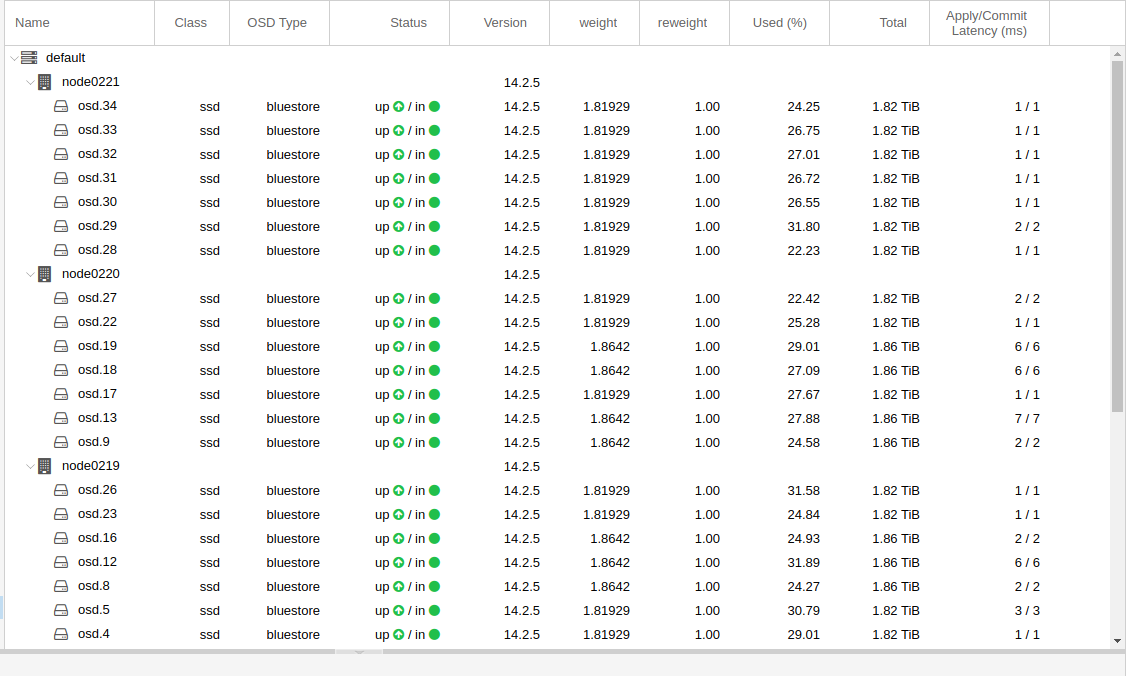
bei einer erweiterung meines ceph storages hab ich gedacht: oh… da ist ein adaptec raid controller drin. mit viel cache und ner backup batterie. und den kann man auch ohne raid betreiben, wenn man den in seinem bios in den HBA mode stellt. gesagt – getan. funktionierte auch erstmal. aber wenn man mal genauer hin schaut, ist die apply/commit latenz bei einigen OSDs um ein vielfaches hoeher, als bei den anderen. hier nur ein beispiel bild, bei dem die werte noch “relativ” niedrig waren. (die node in der mitte des screenshots)
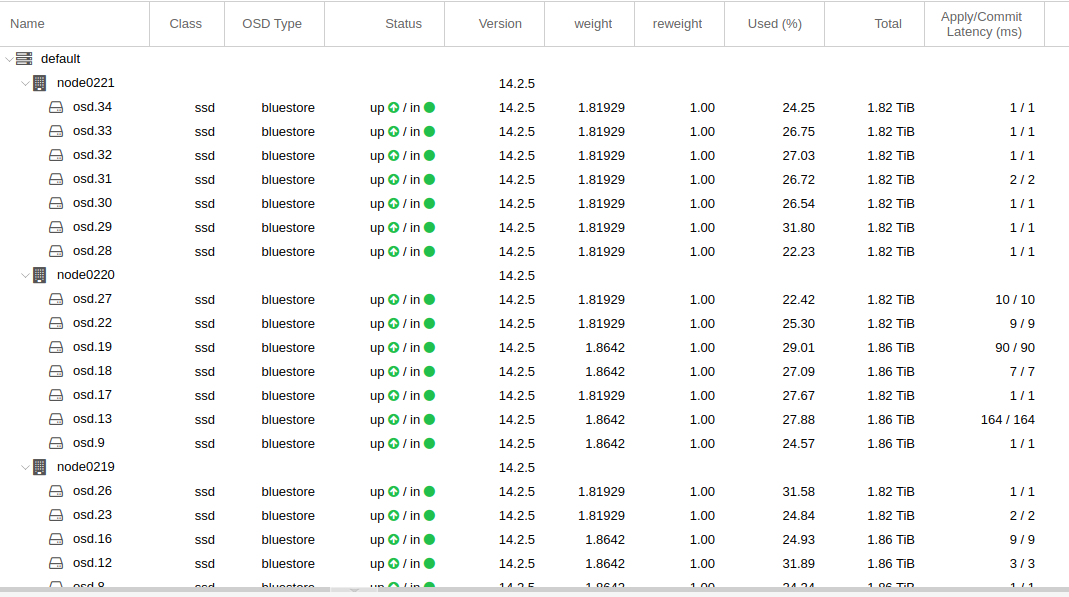
tja – mein gedanke mit “der adaptec controller kanns doch bestimmt besser, als die schnoeden onboard sata dinger” … war dann wohl nix. die ceph doku schreibt “Disk controllers also have a significant impact on write throughput. Carefully, consider your selection of disk controllers to ensure that they do not create a performance bottleneck.”
also controller rausgerissen und die ganze sata kabelage ausgetauscht und die onboard intel controller benutzt…. und siehe da.. die latenz ist “normal”:
kann man auch wunderschoen beim “IO delay” (in blau) erkennen:

auch die proxmox doku schreibt dazu:
“Avoid RAID
As Ceph handles data object redundancy and multiple parallel writes to disks (OSDs) on its own, using a RAID controller normally doesn’t improve performance or availability. On the contrary, Ceph is designed to handle whole disks on it’s own, without any abstraction in between. RAID controller are not designed for the Ceph use case and may complicate things and sometimes even reduce performance, as their write and caching algorithms may interfere with the ones from Ceph.”
jaja… ist ja gut. wie immer erstmal vorher lesen. aber am besten lernt man natuerlich aus den eigenen fehlern 😉
linux: die seriennummer einer festplatte rausfinden
da gibt es mehrere moeglichkeiten. ein paar davon hier gelistet.
command:
udevadm info --query=all --name=/dev/sda | grep ID_SERIAL_SHORT
output:
E: ID_SERIAL_SHORT=1828E1487BE33
command:
hdparm -I /dev/sda | grep 'Serial\ Number'
output:
Serial Number: 1828E1487BE33
command:
lshw -class disk|grep serial
output:
serial: 1828E1487BE33
command:
smartctl -i /dev/sda | grep Serial
output:
Serial Number: 1828E1487BE33
command:
lsblk --nodeps -o name,serial|grep sda
output:
sda 1828E1487BE33
command:
ls -al /dev/disk/by-id/|grep -e sda$|grep -v wwn
output:
lrwxrwxrwx 1 root root 9 Nov 13 05:23 ata-CT500MX500SSD1_1828E1487BE33 -> ../../sda
ich hoffe, dass es etwas neuer ist…
bei einem $kunden musste ich eine “aktuelle” software installieren. bei dieser werden ordnungsgemaess die verwendeten komponenten aufgelistet. ich hoffe allerdings, dass diese komponenten etwas neuer sind, als das, was im copyright teil aufgefuehrt wird….
![]()
citrix: error cannot connect to 0.0.0.2
ich musste unter linux (mint) mit der citrix workspace app arbeiten. beim laden der ica-datei kam der fehler “error cannot connect to 0.0.0.2 appname”. hier die loesung… irgendwo beim googlen gefunden… weiss nur nicht mehr wo:
cd /opt/Citrix/ICAClient/keystore/
sudo rm -r cacerts
sudo ln -s /etc/ssl/certs cacerts
