Tag: proxmox
mal ne runde ssd’s getauscht…
momentan laufen im “home rz” um die 35 VMs.. und der plattenplatz ging langsam zu neige. (ein ceph cluster darf man ja nie voll machen!)
also mal schlappe 15 stueck 1 tb ssds gekauft und die 500 gb dinger im laufenden betrieb eine nach der anderen ausgetauscht.
das reicht mir wieder ne ganze weile 🙂
ceph und festplattencontroller
man muss ja selbst seine erfahrungen machen mit ceph & co…. die leute von proxmox schreiben in ihren forumsbeitraegen auch immer, dass man seine hardware vor dem betrieb testen soll.
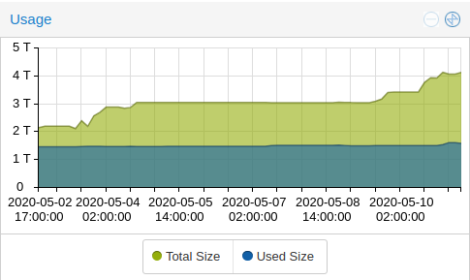
bei einer erweiterung meines ceph storages hab ich gedacht: oh… da ist ein adaptec raid controller drin. mit viel cache und ner backup batterie. und den kann man auch ohne raid betreiben, wenn man den in seinem bios in den HBA mode stellt. gesagt – getan. funktionierte auch erstmal. aber wenn man mal genauer hin schaut, ist die apply/commit latenz bei einigen OSDs um ein vielfaches hoeher, als bei den anderen. hier nur ein beispiel bild, bei dem die werte noch “relativ” niedrig waren. (die node in der mitte des screenshots)
tja – mein gedanke mit “der adaptec controller kanns doch bestimmt besser, als die schnoeden onboard sata dinger” … war dann wohl nix. die ceph doku schreibt “Disk controllers also have a significant impact on write throughput. Carefully, consider your selection of disk controllers to ensure that they do not create a performance bottleneck.”
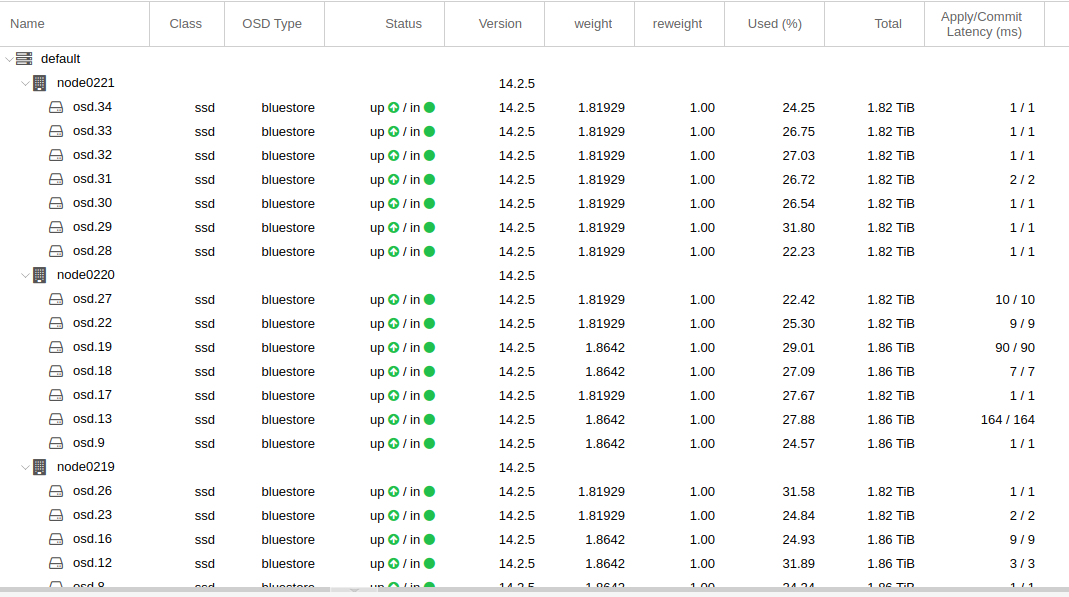
also controller rausgerissen und die ganze sata kabelage ausgetauscht und die onboard intel controller benutzt…. und siehe da.. die latenz ist “normal”:
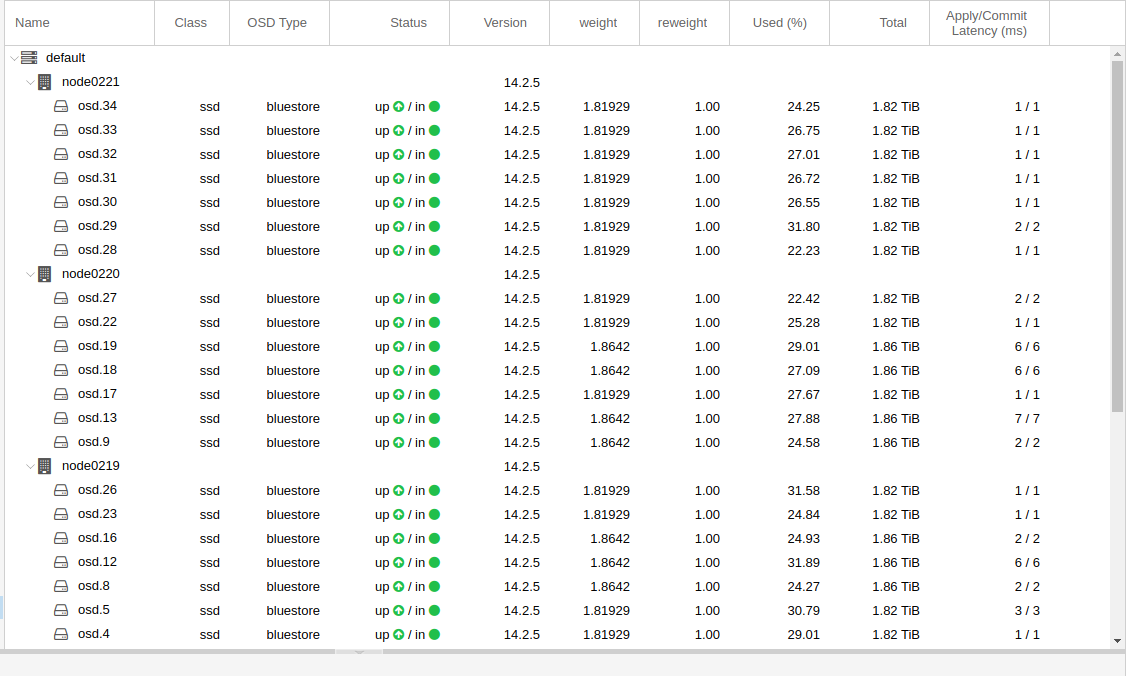
kann man auch wunderschoen beim “IO delay” (in blau) erkennen:

auch die proxmox doku schreibt dazu:
“Avoid RAID
As Ceph handles data object redundancy and multiple parallel writes to disks (OSDs) on its own, using a RAID controller normally doesn’t improve performance or availability. On the contrary, Ceph is designed to handle whole disks on it’s own, without any abstraction in between. RAID controller are not designed for the Ceph use case and may complicate things and sometimes even reduce performance, as their write and caching algorithms may interfere with the ones from Ceph.”
jaja… ist ja gut. wie immer erstmal vorher lesen. aber am besten lernt man natuerlich aus den eigenen fehlern 😉
ceph filestore osd in bluestore umwandeln
um problemen beim umstieg von proxmox 5 auf 6 aus dem weg zu gehen, wollte ich alle “alten” OSDs von filestore auf bluestore “umwandeln”. ausserdem solls ja noch ein quentchen perforemance bringen. es gab auch mindestens noch einen grund, der mir aber entfallen ist.
auf jeden fall hatte ich fuer diesen zweck irgendwann und irgendwo mal ein scriptchen gefunden. das schaut so aus:
ID=$1
echo "ceph osd out $ID"
ceph osd out $ID
# wait to start ceph remapping all things
sleep 10
while ! ceph health | grep HEALTH_OK ; do sleep 10 ; done
echo "systemctl stop ceph-osd@$ID.service"
systemctl stop ceph-osd@$ID.service
sleep 10
DEVICE=`mount | grep /var/lib/ceph/osd/ceph-$ID| cut -f1 -d"1"`
umount /var/lib/ceph/osd/ceph-$ID
echo "ceph-disk zap $DEVICE" ----> /dev/sdd1 das geht net
ceph-disk zap $DEVICE
ceph osd destroy $ID --yes-i-really-mean-it
echo "ceph-disk prepare --bluestore $DEVICE --osd-id $ID"
ceph-disk prepare --bluestore $DEVICE --osd-id $ID
#wait some seconds for metatdata visible
sleep 10;
ceph osd metadata $ID
ceph -s
echo "wait for cluster ok"
while ! ceph health | grep HEALTH_OK ; do echo -e "."; sleep 10 ; done
ceph -s
echo " proceed with next"
das ding als ausfuehrbares script abspeichern und der nummer der umzuwandelnden OSD als uebergebenen parameter starten. natuerlich kann man das auch in einer kleinen for schleife fuer alle OSDs machen. die alte filestore OSD wird aus dem cluster rausgenommen und als neue bluestore OSD wieder eingehaengt. natuerlich muss die ganze disk dann wieder syncen. ist also besser, wenn man eine nach der anderen macht.
proxmox: remove dead ceph node (osd/mon) after removing cluster node
after removing a pve cluster node that was also a ceph osd and monitor node i realised that i forgot to remove the ceph stuff before removing the node from the cluster. there is no possibility to remove it with the pve gui, so i have to do it on the command line.
to delete it from the ceph crush map:
ceph osd crush rm nodenametoremove
to remove the monitor:
ceph mon remove nodenametoremove
the edit the file /etc/ceph/ceph.conf and remove the complete section for the node.
then edit the file /etc/ceph/storage.conf and remove the ip address of the dead monitor node. this step can also be done via the gui.
proxmox: eine partition als osd nutzen
gleich vorneweg: nicht offiziell von proxmox unterstuetzt, aber (fuer mich) funktionieren tuts. 😉
fuer meine aktuelle “spielwiesen-evaluierung” habe ich als boot platte eine 500 GB ssd gekauft. da das betriebsystem und swap nur wenige gigabytes benoetigen, moechte den restlichen platz als OSD fuer ceph verwenden. proxmox unterstuetzt von haus aus nur kompletten festplatten als OSD. mit ein paar tricks kann man das aber trotzdem eintueten. dafuer muessen ein paar vorraussetzungen eingehalten und die folgenden schritte ausgefuehrt werden.
1. als grundlage habe ich ein debian stretch installiert. dabei waehlt man am besten den modus “expert install” aus, da man nur in diesem den typ der partition table der festplatte setzen kann. der installer macht standardmaessig eine MBR patrition table, aber wir brauchen zwingend eine des typs GPT!
2. das debian system samt proxmox und ceph installieren (siehe proxmox wiki)
3. danach muss die OSD partition wie folgt angelegt und praepariert werden:
als erstes setzen wir ein paar variablen… der partition typecode “is designating a Ceph data disk”
PTYPE_UUID=4fbd7e29-9d25-41b8-afd0-062c0ceff05d
die festplatte, die verwendet werden soll:
disk=/dev/sda
die nuemmer der partition ist die naechste freie nummer:
part=4
und eine zufaellige UUID wird benoetigt, um die neue OSD zu identifizieren:
(wenns nicht funktioniert, vorher noch das paket “uuid-runtime” installieren)
OSD_UUID=`uuidgen -r`
wenn all diese variablen gesetzt sind, kann mit dem sgdisk kommando die neue partition angelegt werden:
sgdisk --largest-new=$part --change-name="${part}:ceph" --partition-guid=${part}:$OSD_UUID --typecode=${part}:$PTYPE_UUID $disk
der output koennte so aussehen:
Setting name!
partNum is 3
REALLY setting name!
Warning: The kernel is still using the old partition table.
The new table will be used at the next reboot or after you
run partprobe(8) or kpartx(8)
The operation has completed successfully.
um die proxmox boardmittel nutzen zu koennen, muss man ein bischen in einem perl script rumpfuschen… und zwar das: /usr/share/perl5/PVE/API2/Ceph.pm
vorher bitte eine sicherungskopie anlegen, damit man die originale datei im anschluss wiederherstellen kann. (funktioniert mit pve 5.2)
suche in der datei nach diesem string:
$devname =~ s|/dev/||;
…und kommentiere diese und die folgenden zeilen bis zu dieser aus:
my $devpath = $diskinfo->{devpath};
dann fuege diese zeile darunter ein:
my $devpath = $devname;
jetzt suche nach
my $cmd = ['ceph-disk', 'prepare', '--zap-disk',
…und entferne am ende das argument “–zap-disk”, so dass die zeile so aussieht:
my $cmd = ['ceph-disk', 'prepare',
dann kann man endlich die OSD erstellen:
pveceph createosd /dev/sda4 --bluestore=0
(wenn die fehlermeldung “not a valid block device” kommt, ist noch ein reboot notwendig, damit der kernel die oben abgeaenderte partition table frisst.)
ich habe hier bluestore auf 0 gesetzt, da es bei mir nicht funktioniert hatte. (ich bin mir garnicht sicher, ob man bluestore ueberhaupt mit einer partition verwenden kann… vermutlich eher nicht.) so wird der herkoemmliche typ “filestore genommen und die partition mit xfs formatiert.
der output koennte so aussehen:
create OSD on /dev/sda4 (xfs)
meta-data=/dev/sda4 isize=2048 agcount=4, agsize=29150209 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0, rmapbt=0, reflink=0
data = bsize=4096 blocks=116600833, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=56934, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
und zum schluss noch die OSD aktivieren, wodurch die partition gemountet und der zugehoerige OSD daemon gestartet wird
ceph-disk activate /dev/sda4
und schon ist die partiton unter proxmox als OSD verfuegbar. in der proxmox oberflaeche wird die ganze festplatte als OSD angezeigt, was mich aber nicht weiter stoert 😉
neue “server hardware” fuers home lab
man braucht ja noch projekte… ich baue mir mal ein neues proxmox cluster fuer zuhause. die sache mit den intel nuc’s ist zwar ganz schick, aber die loesung mit externen usb festplatten is doch irgendwie doof. fuer 90% meiner sachen reicht das vollkommen aus, aber manchmal darfs auch ein klein bischen mehr performance sein. da der ganze schrabel noch irgendwie im keller in mein kleines 19 zoll wandrack rein passen soll, ist die auswahl an bauform sehr gering. drei kurze 1he gehaeuse hab ich guenstig in UK erstanden. in den 5 1/4 zoll einbauschacht passt ein 6×2,5 zoll wechselrahmen dings rein, in welches dann ssd’s verbaut werden.

demnach brauche ich auch ein (mini itx) motherboard mit mindestens 6 sata anschluessen. die wahl fiel auf ein asus p10s-i, in welches man alle moeglichen cpu’s mit sockel 1151 stecken kann. angefangen von guenstigen celerons und pentiums bis hin zu guten xeons. zum evaluieren habe ich mir erstmal einen guenstigen pentium 2-core geholt. und prompt bin ich drauf rein gefallen und die cpu war zu neu fuer das board. haette ich vorher mal genauer in die kompatibilitaetsliste geschaut…
auf jeden fall hat das board zwei gigabit nics, welche dann im bond laufen sollen. mal schauen, ob ich spaeter noch eine 10gbe netzwerkkarte da rein bekomme. ein kleines zusatzplatinchen gibts auch, welches dem board zu einem IPMI interface verhilft, fuer welches auch schon ein dedizierter lan port verbaut ist.
RAM gibts fuer den anfang 16 GB an einem stueck. spaeter werden es dann sicherlich 32 GB als “usefull size” werden.

ssds sind ja gerade am billiger werden. anfangen werde ich mit 2x 500gb crucial mx500 als ceph osd’s. vier freie slots lassen noch luft nach oben.
die gehaeuse sind also gesetzt… und wenn dieser erste “prototyp” sich als brauchbar herausstellt, werde ich noch die innereien fuer die beiden anderen gehaeuse bestellen. installiert ist die kiste auf jeden fall schonmal. reingehaengt ins bereits laufende proxmox/ceph cluster ist eine migration ohne downtime und mit anschliessendem rueckbau der “alten” hardware moeglich. einfach nur genial 🙂
proxmox spontane reboots oder alle festplatten “verloren”
in einem proxmox/ceph cluster mit insgesamt sieben nodes sind vier identische nodes nur für den ceph storage zustaendig. alles supermicro x8dtl-3f mit ssds und 10gbit nics.
irgendwann… ich weiss nicht genau wann… aber auf jeden fall nach dem update auf debian stretch und pve5 hatten diese vier server problemchen. erstmal sah es so aus, als ob es mehrere verschiedene probleme sind.
1. in einem zeitraum von 1 bis 7 tage booteten die server spontan und ohne erkenntlichen grund. keine eintraege im syslog und nichts im bios/ipmi eventlog zu sehen.
2. weniger haeufig kam es vor, dass ein node zwar noch “online” war, aber alle seine festplatten “verloren” hat. seh dann auf dem bildshirm so aus:
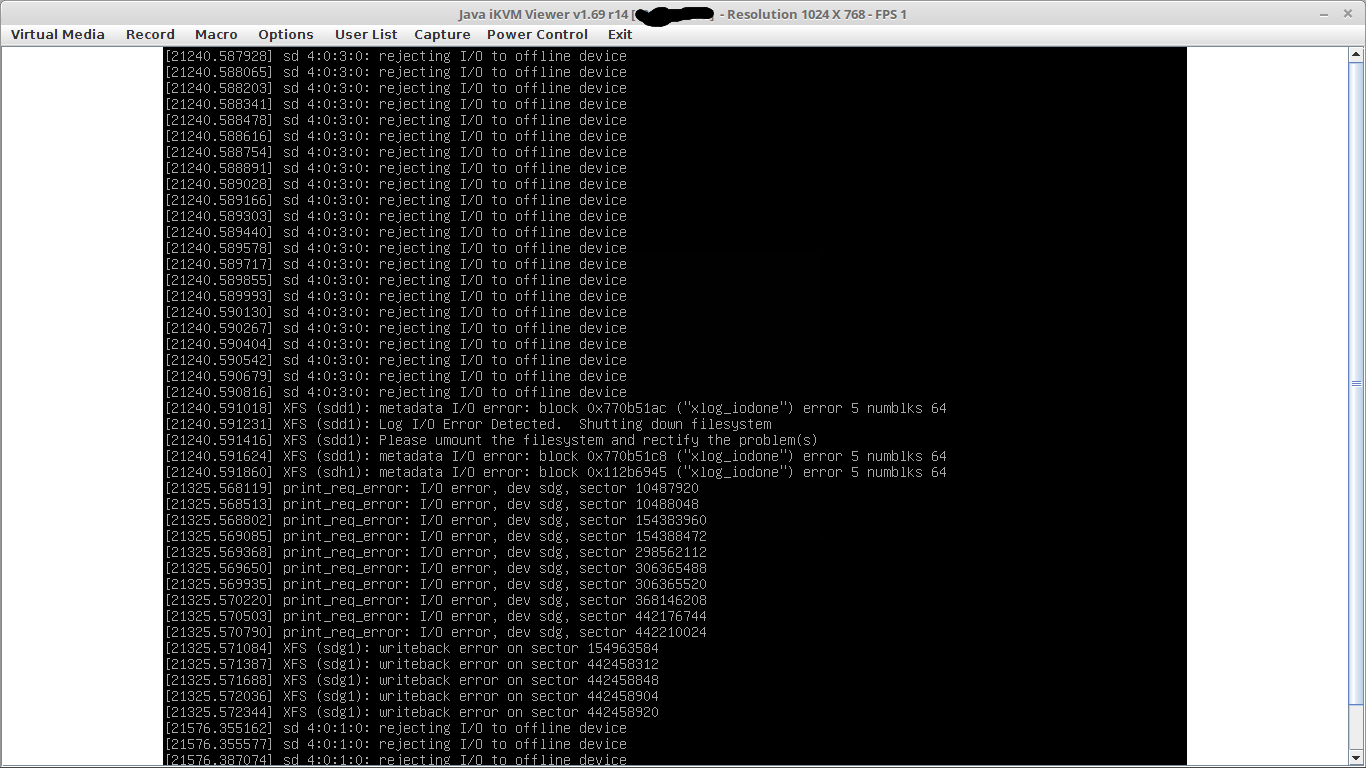
3. die onboard netzwerkkarten haben rumgezickt, was im logfile dann so aussah:

das hat sich dann im sekundentakt wiederholt
4. selten bekam ich meldungen wie diese auf den schirm:
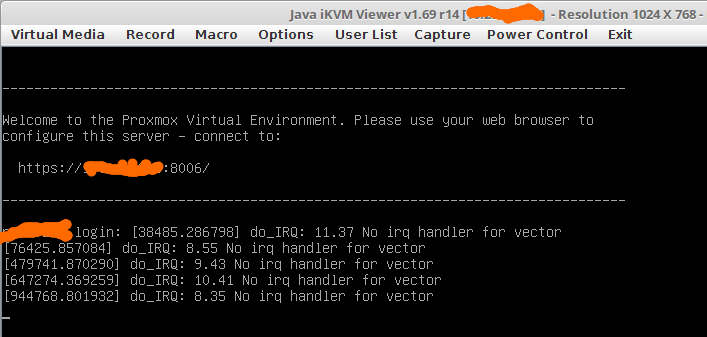
wie sich aber rausstellte, war das genau das ausschlaggebende! falls noch was im syslog zu sehen war (eher garnicht ausser bei dem nic flapping), dann war auch immer so eine meldung unmittelbar davor zu sehen.
nach ein wenig googlen kam heraus, dass der “irqbalanced” fuer diese meldungen verantwortlich ist. der irqbalanced kann im laufenden betrieb irq’s bei bedarf auf eine andere cpu mappen. wenn man google nach diesem ding fragt, bekommt man viele aussagen. von “braucht man nicht, weil aktuelle kernels das von alleine koennen” bis “sehr wichtig bei hoher last fuer performanceoptimierungen”.
ich hab dann kurzerhand in der datei /etc/default/irqbalance den parameter “IRQBALANCE_ONESHOT=YES” gesetzt. in der beschreibung dazu steht: “after starting, wait for a minute, then look at the interrupt load and balance it once; after balancing exit and do not change it again.”
….und was soll ich sagen. seit vier wochen habe ich nun ruhe und die server lauifen durch 🙂
fuer eine genaua analyse und warum das seit wann auftritt… puh.. da fehlt mir die zeit. ich hab mich lange genug damit beschaeftigt und nun laufen die kisten wieder rund.
ceph blinkenlights
zu dem beitrag mit dem proxmox/ceph cluster gibts noch ein schickes video:
und das im dunkeln anzusehen… hach… das kann jeden nerd dazu bringen, ewigkeiten davor zu stehen und einfach nur stur auf das geblinke zu starren. so wie bei einem lagerfeuer.
ceph recovery io
hab ichs schonmal gesagt? ich liebe ceph. und bei solchen datenraten beim recovery … boah…
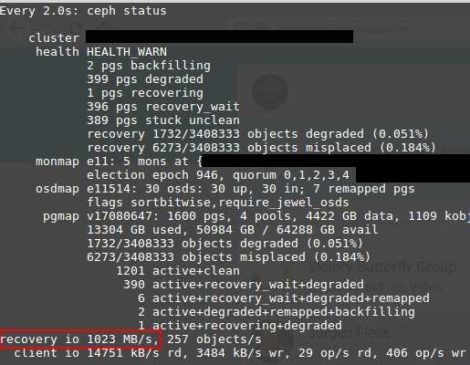
(nein, das ist nicht von meinem “spiel cluster” auf intel NUC basis mit usb3 platten 😉 )
proxmox/ceph cluster in miniatur
ich lehne mich jetzt mal aus dem fenster uns behaupte, dass ich eines der “kleinsten” proxmox/ceph cluster habe, die je so gebaut wurden. klein im sinne von physischen abmessungen. die hardware ausstattung ist zwar nicht so der high performance kram, aber fuer die groesse recht ansehnlich.
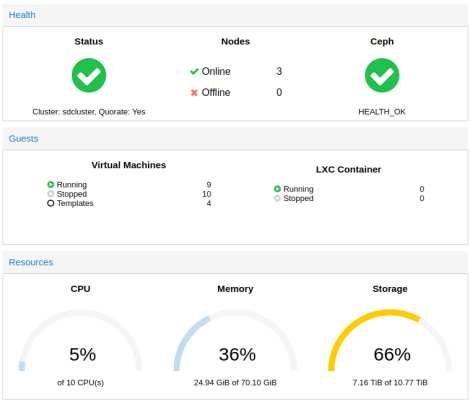
3x intel NUC mit 9x 2,5 zoll usb 3.0 platten und ein synology slim nas. da eckdaten:
10 CPU cores
70 GB ram
6 TB ceph storage (brutto)
4 TB nfs storage (synology)
fuer das, was man so zuhause rumexperimentieren muss, langt mir das (fuers erste) 😀
das ganze sieht dann so aus: (erste ausbaustufe)

der hdd platz im ceph war mir bald zu klein, so dass ich noch drei weitere platten dran gehaengt hab:

da aber die platten nun dicht an dicht gepackt waren, musste ich mir was einfallen lassen, da die einfach zu warm wurden. dazu hab ich baumarkt ein paar alu profile gekauft, zersaegt und mit sekundenkleber zusammengebastelt.

was dann am ende so aussieht:

so ist dann etwas luft zwischen den platten und das alu kann vielleicht ein bischen waerme ableiten. wenns nicht reicht, kann ich noch ein oder zwei luefter dahinter haengen.
