Tag: linux
amavisd tmp verzeichnis permission denied
eine frische installation von amavis und clamav werkelt bei debian wheezy nicht out of the box. diese berechtigungsprobleme werden im mail.og ausgegeben:
Dec 21 13:27:09 mxxx amavis[20283]: (20283-01) (!)run_av (ClamAV-clamd) FAILED - unexpected , output="/var/lib/amavis/tmp/amavis-20131221T132753-20283-SD4gQJVU/parts: lstat() failed: Permission denied. ERROR\n"
Dec 21 13:27:09 mxxx amavis[20283]: (20283-01) (!)ClamAV-clamd av-scanner FAILED: CODE(0x1c8e750) unexpected , output="/var/lib/amavis/tmp/amavis-20131221T132753-20283-SD4gQJVU/parts: lstat() failed: Permission denied. ERROR\n" at (eval 111) line 899.
Dec 21 13:27:09 mxxx amavis[20283]: (20283-01) (!)WARN: all primary virus scanners failed, considering backups
grund ist – wer haette das ahnen koennen – fehlende berechtigung. da das verbiegen dieser im dateisystem bei updates oft nach hinten losgeht, muss man die gruppenberechtigung der user anpassen. ich habs mit der grossen keule gemacht 😉
usermod -a -G clamav amavis
usermod -a -G clamav clamav
usermod -a -G amavis clamav
usermod -a -G amavis amavis
danach die dienste neu starten und gut.
service clamav-daemon restart
service amavis restart
service postfix restart
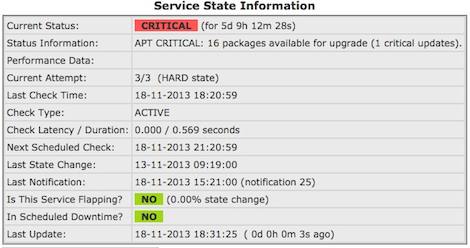
nagios + debian wheezy automatic apt-get update
mein nagios soll auch ueberwachen, ob ein debian rechner updates bekommen soll. das probem ist, dass der nagios user oder in meinem falle der user, mit dem der nrpe agent ausgefuehrt wird, keine berechtigungen hat, ein “apt-get update” auszufuehren.
in debian wheezy gibts dazu bereits ein passendes hilfsmittel. (in den vorgaengerversionen auch schon, aber das configfile unterscheidet sich in ein paar punkten). ein entsprechender cronjob mit dem namen “apt” ist schon vorhanden in /etc/cron.daily/. damit der auch was tut, muss man die datei “/etc/apt/apt.conf.d/02periodic” mit folgendem inhalt anlegen:
APT::Periodic::Enable "1";
APT::Periodic::Update-Package-Lists "1";
APT::Periodic::Download-Upgradeable-Packages "1";
wenn man druff geschickt ist, kann man die updates damit auch installieren lassen. aber das will ich nicht.
und schwups:
dpkg: warning: package not in database
wenn man ein debian system klonen will und es kommt zu so einer fehlermeldung:
dpkg: warning: package not in database [...]
dann einfach mal dieses paket nach installieren:
apt-get install dselect
danach dselect starten und ein “Update” und “Install” durchfuehren. und schon kann man mit oben verlinkter anleitung weiter machen 😉
bash: groesse aller unterverzeichnisse
immer wieder gern gebraucht. vielleicht sollte ich mir mal nen alias dafuer anlegen?
for i in `ls -1`; do if [[ -d $i ]]; then du -sm $i; fi; done
wenn die mysql replikation mal klemmt (2)
neulich habe ich mal beschrieben, wie man einen einzelnen befehl bei der replikation auslaesst, wenn er denn zu problemen fuehrt.
ein anderes szenario ist, wenn mal stromausfall ist oder eine virtuelle maschine einfach ausgeschaltet bzw. “gekillt” wird. dann kann der master vielleicht nicht alles transaktionen in das replikations log schreiben oder sowas in der art. im logfile ist dann sowas zu finden:
MySQL Error: Client requested master to start replication from impossible position
zuerst den status auf dem master checken:
mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.003615 | 4994240 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
dann den slave stoppen, seine position im aktuellen log mitteilen, bei der er weiter machen soll und wieder starten:
slave stop;
CHANGE MASTER TO MASTER_HOST='db.domain.tld', MASTER_USER='repl',MASTER_PASSWORD='geheim', MASTER_LOG_FILE='mysql-bin.003615', MASTER_LOG_POS=0;
slave start;
und dann kann man nur hoffen, dass nicht allzu viel kaputt geht. weil das ohne genauer nachzusehen erstmal quasi ein undefinierter zustand ist. wenns schief geht, empfihelt sich doch die standard methode, um eine mysql replikation einzurichten. also haupt datenbank stoppen, snapshot ziehen, auf slave kopieren, einrichten.. blablabla..
Authentication service cannot retrieve authentication info
merke… einfach mal user und gruppen in die /etc/passwd und /etc/group eintragen und die /etc/shadow vergessen ist doof. ssh logins klappen dann nicht. und wenn man das passwort setzen will, kommt sowas:
~$ passwd username
passwd: Authentication service cannot retrieve authentication info.
bind: zone transfer deferred due to quota
neulich im logfile eines bind dns servers gefunden:
25-Sep-2013 09:40:45.611 zone domain.tld/IN/trusted: zone transfer deferred due to quota
keine panik! die anzahl gleichzeitiger zonen transfers ist beschraenkt. (ich bin noch auf der suche nach der einstellung und dem default wert.) der bind holt das aber ziemlich bald nach.
bind …but using default configuration file
auf debian systemen kommts beim upgrade auf neuere bind versionen (bzw. des ganzen systems) dazu, dass starten des bind diese warnung ausgespuck wird:
WARNING: key file (/etc/bind/rndc.key) exists, but using default configuration file (/etc/bind/rndc.conf)
abhilfe schafft es, die datei /etc/bind/rndc.conf zu loeschen. vorher pruefen, ob in der /etc/bind/rndc.key der passende key drin steht. dann noch in der datei /etc/bind/named.conf pruefen, ob diese zeile vorhanden ist und ggf. einfuegen:
include "/etc/bind/rndc.key";
opsview und check_mysql_performance
heute wollte ich einen db server mit opsview (core) ueberwachen. das normale host template “Database – MySQL” funktionierte tadellos. als ich das etwas umfangreichere “Database – MySQL Server” angeschaltet habe, gabs nur fehler. der status war bei allen “(Return code of 255 is out of bounds)”
nachdem ich dann erst einmal rausgefunden habe, wie man den mysql check überhaupt konfiguriert:
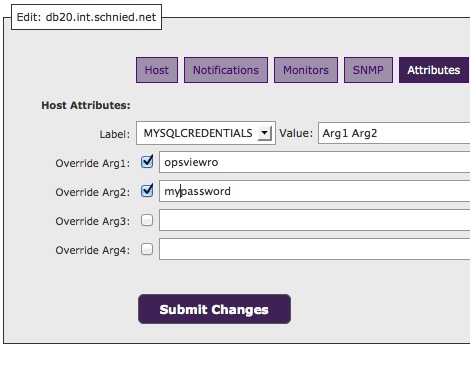
…war das ergebnis noch nicht besser. also mal husch den check mit einem beliebigen parameter auf der commandline ausgefuehrt mit folgendem ergebnis:
root@nagios:~# /usr/local/nagios/libexec/check_mysql_performance -H db.int.domain.tld -u opsview -p mypassword --metricname=Connections -w 20 -c 30
Goto undefined subroutine &Carp::shortmess_real at /usr/share/perl/5.10/Carp.pm line 41.
die loesungen bei google waren recht uebersichtlich. eines hat jedoch die erhoffte abhilfe geschaffen. in der datei /usr/local/nagios/libexec/check_mysql_performance muss folgende ergaenzung gemacht werden (“use Carp::Heavy;” an der richtigen stelle eingefuegt):
[...]
use strict;
use warnings;
use FindBin qw($Bin);
use Carp::Heavy;
use lib "$Bin/../perl/lib", "/usr/local/nagios/libexec";
use Nagios::Plugin;
[...]
im hintergrund sind die knapp 40 weiteren checks natuerlich fleissig weiter gelaufen, so dass ich beim naechsten test folgende meldung bekam:
root@nagios:~# /usr/local/nagios/libexec/check_mysql_performance -H db.int.domain.tld -u opsview -p mypassword --metricname=Connections -w 20 -c 30
DBI connect('host=db.int.domain.tld','opsview',...) failed: Host 'nagios.int.domain.tld' is blocked because of many connection errors; unblock with 'mysqladmin flush-hosts' at /usr/local/nagios/libexec/check_mysql_performance line 477
hmm… sind also so viele fehler aufgetreten, dass der mysql server die anfragen erstmal blockiert hat. im normalen nagios logfile steht nicht wirklich was aussagekraeftiges drin. also debugging einschalten, in dem man in der datei /usr/local/nagios/etc/nagios.cfg diese zeiel angepassen und opsview neu starten:
[...]
debug_level=16
[...]
dann wird in die datei /usr/local/nagios/var/log/nagios.debug protokolliert. und siehe da…
[1380044880.745551] [016.0] [pid=8622] ** Handling check result for service 'MySQL SSL Session cache overflows' on host 'db.int.domain.tld' from 'Core Worker 8626'...
[1380044880.745588] [016.1] [pid=8622] HOST: db.int.domain.tld, SERVICE: MySQL SSL Session cache overflows, CHECK TYPE: Active, OPTIONS: 0, SCHEDULED: Yes, RESCHEDULE: Yes, EXITED OK: Yes, RETURN CODE: 13, OUTPUT: (No output on stdout) stderr: can't write into /tmp/nagios_mysql_perf_db.int.domain.tld_a3sApVWRDav1..tmp: Permission denied at /usr/local/nagios/libexec/check_mysql_performance line 597.
aha… also permission denied auf die datei “/tmp/nagios_mysql_perf_db.int.domain.tld_a3sApVWRDav1..tmp”
das ist so, weil ich vorher den check als root ausgefuehrt habe. deswegen ist der besitzer nun root und der user nagios kann die datei nicht loeschen.
root@nagios:~# ls -lisa /tmp/
total 68
5406721 4 drwxrwxrwt 6 root root 4096 Sep 24 19:50 .
2 4 drwxr-xr-x 21 root root 4096 Jan 28 2013 ..
[...]
5406744 12 -rw-r--r-- 1 root root 8194 Sep 24 19:38 nagios_mysql_perf_db.int.domain.tld_a3sApVWRDav1..tmp
5406731 8 -rw-rw-r-- 1 nagios nagios 7657 Sep 24 19:51 nagios_mysql_perf_localhost_a3HhY0MKWDmPo.tmp
[...]
also hurtig loeschen und schon funktioniert die sache wieder.
bei einem dutzend checks musste ich die standardwerte fuer die alarme in den checks anpasssen, da diese total daneben waren. vielleicht muss ich auch ein paar der cheks raus schmeissen, weil total irrelevant fuer meine zwecke. schauen wir mal…
midnight commander + mac + insert taste
wer einen mac mit osx hat, eine bloede mac tastatur ohne “insert” taste und mal nen mc (midnight commander) im terminal (remote) benutzen will, der wird schon oft geflucht haben. die insert taste wird naemlich zum markieren einzelner zeilen benoetigt.
abhilfe schafft die tastenkombination “CRTL + T” 😉
