Tag: mysql
phpmyadmin mit fail2ban absichern
seit phpmyadmin 4.8 gibt es endlich eine logging funktion fuer die fehlgeschlagenen logins. diese kann man dann wunderbar per fail2ban auswerten. frueher war das eher eine wurschtelei mit customized apache logs oder gar aenderungen an den installierten phpmyadmin dateien (welche nach einem update wieder futsch waren). standardmaessig ist diese logging funktion auch enabled und schreibt die fehlgeschlagenen logins ins php error logfile oder syslog. der parameter in der config.inc.php heisst $cfg[‘AuthLog’] und hat den wert “auto”. phpmyadmin entscheidet dann selbststaendig, ob es ins php error log oder syslog schreibt. in meinem falle machte es das ins php error log. wenn nicht, kann man den wert entsprechend setzen.
hier ist das die datei /var/www/webxxxx/logs/priv/php_errors.log. die eintraege im log haben dieses format:
[19-May-2019 21:07:49 Europe/Berlin] user denied: phpmyadmin (mysql-denied) from 46.246.65.167
zuerst muss man einen entsprechenden filter fuer fail2ban konfigurieren. dazu einfach die datei /etc/fail2ban/filter.d/phpmyadmin.conf mit diesem inhalt anlegen:
[Definition]
denied = mysql-denied|allow-denied|root-denied|empty-denied
failregex = ^.*(%(denied)s).* from $
ignoreregex =
beim debuggen seiner eigenen regex kann die seite debuggex.com sehr hilfreich sein. testen kann man seinen selbst erstellten filter mit diesem befehl:
fail2ban-regex /var/www/webxxxx/logs/priv/php_errors.log /etc/fail2ban/filter.d/phpmyadmin.conf
im ergebnis sollten dann irgendwie so in der art aussehen:
[...]
Lines: 31 lines, 0 ignored, 10 matched, 21 missed
[...]
bei “matched” sollte eine entsprechende anzahl groesser 0 auftauchen. wenn dem so ist, braucht man noch eine “jail” konfiguration fuer phpmyadmin. dazu die datei
/etc/fail2ban/jail.d/phpmyadmin.conf mit diesem inhalt anlegen:
[phpmyadmin]
enabled = true
port = http,https
filter = phpmyadmin
logpath = /var/www/webxxxx/logs/priv/php_errors.log
einmal neu laden ….
service fail2ban reload
… und einfach mal ein paar fehlerhafte loginversuche ausloesen. im php error log sieht das so aus:
[24-May-2019 07:51:45 Europe/Berlin] user denied: dasdsadsadas (empty-denied) from 87.xxx.xx.xx
[24-May-2019 07:51:46 Europe/Berlin] user denied: dasdsadsadas (empty-denied) from 87.xxx.xx.xx
[24-May-2019 07:51:47 Europe/Berlin] user denied: dasdsadsadas (empty-denied) from 87.xxx.xx.xx
[24-May-2019 07:51:48 Europe/Berlin] user denied: dasdsadsadas (empty-denied) from 87.xxx.xx.xx
[24-May-2019 07:51:49 Europe/Berlin] user denied: dasdsadsadas (empty-denied) from 87.xxx.xx.xx
und korrespondierend im fail2ban logfile:
/var/log/fail2ban.log
2019-05-24 07:51:45,862 fail2ban.filter [1144]: INFO [phpmyadmin] Found 87.xxx.xx.xx
2019-05-24 07:51:46,936 fail2ban.filter [1144]: INFO [phpmyadmin] Found 87.xxx.xx.xx
2019-05-24 07:51:47,952 fail2ban.filter [1144]: INFO [phpmyadmin] Found 87.xxx.xx.xx
2019-05-24 07:51:48,832 fail2ban.filter [1144]: INFO [phpmyadmin] Found 87.xxx.xx.xx
2019-05-24 07:51:49,592 fail2ban.filter [1144]: INFO [phpmyadmin] Found 87.xxx.xx.xx
2019-05-24 07:51:50,303 fail2ban.actions [1144]: NOTICE [phpmyadmin] Ban 87.xxx.xx.xx
2019-05-24 08:01:51,276 fail2ban.actions [1144]: NOTICE [phpmyadmin] Unban 87.xxx.xx.xx
bei dem jail greifen hier die fail2ban standard werte einer debian 9 installation. nach 5 fehlerhaften logins von einer IP wird diese fuer 10 minuten per iptables geblockt.
that’s it.
mysql replikation “frisch” machen
ich hatte den fall, dass mysql master und slave bei eingerichteter replikation ein paar tage nicht syncen konnten. danach wollte sie auch nicht mehr. um den zustand zu beheben, hier kurz und knapp die schritte beschrieben…
auf dem master:
RESET MASTER;
FLUSH TABLES WITH READ LOCK;
SHOW MASTER STATUS;
den output des kommandos notieren! die session offen lassen, da sonst das read lock aufgehoben wird.
mysqldump -u root -p --all-databases > /tmp/mysqldump.sql
danach den read lock wieder aufheben
UNLOCK TABLES;
das dump file dann z.b. per scp auf den slave kopieren
auf dem slave:
STOP SLAVE;
den dump einspielen:
mysql -uroot -p < mysqldump.sql
master und slave logs syncen:
RESET SLAVE;
CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=98;
...natuerlich mit den werten, die man sich vom master kopiert hat.
danach noch den slave starten:
START SLAVE;
schauen, ob alles fine ist:
SHOW SLAVE STATUS;
irgendwo muss dann stehen:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
That's it!
wenn die mysql replikation mal klemmt (2)
neulich habe ich mal beschrieben, wie man einen einzelnen befehl bei der replikation auslaesst, wenn er denn zu problemen fuehrt.
ein anderes szenario ist, wenn mal stromausfall ist oder eine virtuelle maschine einfach ausgeschaltet bzw. “gekillt” wird. dann kann der master vielleicht nicht alles transaktionen in das replikations log schreiben oder sowas in der art. im logfile ist dann sowas zu finden:
MySQL Error: Client requested master to start replication from impossible position
zuerst den status auf dem master checken:
mysql> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.003615 | 4994240 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
dann den slave stoppen, seine position im aktuellen log mitteilen, bei der er weiter machen soll und wieder starten:
slave stop;
CHANGE MASTER TO MASTER_HOST='db.domain.tld', MASTER_USER='repl',MASTER_PASSWORD='geheim', MASTER_LOG_FILE='mysql-bin.003615', MASTER_LOG_POS=0;
slave start;
und dann kann man nur hoffen, dass nicht allzu viel kaputt geht. weil das ohne genauer nachzusehen erstmal quasi ein undefinierter zustand ist. wenns schief geht, empfihelt sich doch die standard methode, um eine mysql replikation einzurichten. also haupt datenbank stoppen, snapshot ziehen, auf slave kopieren, einrichten.. blablabla..
opsview und check_mysql_performance
heute wollte ich einen db server mit opsview (core) ueberwachen. das normale host template “Database – MySQL” funktionierte tadellos. als ich das etwas umfangreichere “Database – MySQL Server” angeschaltet habe, gabs nur fehler. der status war bei allen “(Return code of 255 is out of bounds)”
nachdem ich dann erst einmal rausgefunden habe, wie man den mysql check überhaupt konfiguriert:
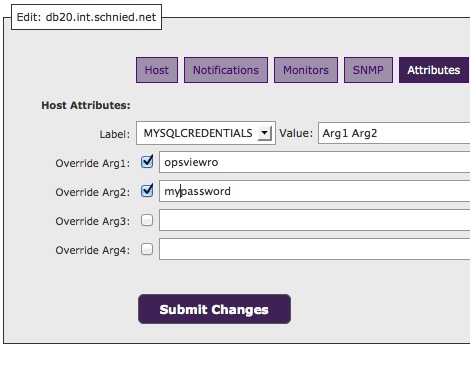
…war das ergebnis noch nicht besser. also mal husch den check mit einem beliebigen parameter auf der commandline ausgefuehrt mit folgendem ergebnis:
root@nagios:~# /usr/local/nagios/libexec/check_mysql_performance -H db.int.domain.tld -u opsview -p mypassword --metricname=Connections -w 20 -c 30
Goto undefined subroutine &Carp::shortmess_real at /usr/share/perl/5.10/Carp.pm line 41.
die loesungen bei google waren recht uebersichtlich. eines hat jedoch die erhoffte abhilfe geschaffen. in der datei /usr/local/nagios/libexec/check_mysql_performance muss folgende ergaenzung gemacht werden (“use Carp::Heavy;” an der richtigen stelle eingefuegt):
[...]
use strict;
use warnings;
use FindBin qw($Bin);
use Carp::Heavy;
use lib "$Bin/../perl/lib", "/usr/local/nagios/libexec";
use Nagios::Plugin;
[...]
im hintergrund sind die knapp 40 weiteren checks natuerlich fleissig weiter gelaufen, so dass ich beim naechsten test folgende meldung bekam:
root@nagios:~# /usr/local/nagios/libexec/check_mysql_performance -H db.int.domain.tld -u opsview -p mypassword --metricname=Connections -w 20 -c 30
DBI connect('host=db.int.domain.tld','opsview',...) failed: Host 'nagios.int.domain.tld' is blocked because of many connection errors; unblock with 'mysqladmin flush-hosts' at /usr/local/nagios/libexec/check_mysql_performance line 477
hmm… sind also so viele fehler aufgetreten, dass der mysql server die anfragen erstmal blockiert hat. im normalen nagios logfile steht nicht wirklich was aussagekraeftiges drin. also debugging einschalten, in dem man in der datei /usr/local/nagios/etc/nagios.cfg diese zeiel angepassen und opsview neu starten:
[...]
debug_level=16
[...]
dann wird in die datei /usr/local/nagios/var/log/nagios.debug protokolliert. und siehe da…
[1380044880.745551] [016.0] [pid=8622] ** Handling check result for service 'MySQL SSL Session cache overflows' on host 'db.int.domain.tld' from 'Core Worker 8626'...
[1380044880.745588] [016.1] [pid=8622] HOST: db.int.domain.tld, SERVICE: MySQL SSL Session cache overflows, CHECK TYPE: Active, OPTIONS: 0, SCHEDULED: Yes, RESCHEDULE: Yes, EXITED OK: Yes, RETURN CODE: 13, OUTPUT: (No output on stdout) stderr: can't write into /tmp/nagios_mysql_perf_db.int.domain.tld_a3sApVWRDav1..tmp: Permission denied at /usr/local/nagios/libexec/check_mysql_performance line 597.
aha… also permission denied auf die datei “/tmp/nagios_mysql_perf_db.int.domain.tld_a3sApVWRDav1..tmp”
das ist so, weil ich vorher den check als root ausgefuehrt habe. deswegen ist der besitzer nun root und der user nagios kann die datei nicht loeschen.
root@nagios:~# ls -lisa /tmp/
total 68
5406721 4 drwxrwxrwt 6 root root 4096 Sep 24 19:50 .
2 4 drwxr-xr-x 21 root root 4096 Jan 28 2013 ..
[...]
5406744 12 -rw-r--r-- 1 root root 8194 Sep 24 19:38 nagios_mysql_perf_db.int.domain.tld_a3sApVWRDav1..tmp
5406731 8 -rw-rw-r-- 1 nagios nagios 7657 Sep 24 19:51 nagios_mysql_perf_localhost_a3HhY0MKWDmPo.tmp
[...]
also hurtig loeschen und schon funktioniert die sache wieder.
bei einem dutzend checks musste ich die standardwerte fuer die alarme in den checks anpasssen, da diese total daneben waren. vielleicht muss ich auch ein paar der cheks raus schmeissen, weil total irrelevant fuer meine zwecke. schauen wir mal…
wenn die mysql replikation mal klemmt
wenn die mysql replikation aufgrund eines fehlers in einem statement mal aussteigt, dann muss man dieses statement einfach weg lassen 😉
im logfile (bei debian /var/log/daemon.log) steht dann so ein kram:
Query caused different errors on master and slave. Error on
master: 'Table '%-.64s' already exists' (1050), Error on
slave: 'You have an error in your SQL syntax; check the manual
that corresponds to your MySQL server version for the right
syntax to use near '' at line 1' (1064).
[...]
[ERROR] Error running query, slave SQL thread aborted. Fix
the problem, and restart the slave SQL thread with "SLAVE
START". We stopped at log 'mysql-bin.003535' position 91778974
oder wenn man sich den slave status auf der commandline ansieht:
SHOW SLAVE STATUS \G
was solch einen output liefert.
mysql> SHOW SLAVE STATUS \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: xxx.xxxxxx.xxx
Master_User: replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.003535
Read_Master_Log_Pos: 97111481
Relay_Log_File: host-relay-bin.007674
Relay_Log_Pos: 91779321
Relay_Master_Log_File: mysql-bin.003535
Slave_IO_Running: Yes
Slave_SQL_Running: No
[...]
wenn da nun “Slave_SQL_Running” auf “No” steht, weiss man, dass die replikation nicht laeuft.
wenn man sich nun sicher ist, dass das naechste statement vom master nicht benoetigt wird (weils wie in diesem falle hier zu einem fehler fuehrt), kann man dieses kommando ausfuehren, um ein statement zu ueberspringen:
SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1;
START SLAVE;
weitere hilfe und bemerkungen dazu auf den mysql development seiten.
you can’t use locks with log tables when doing lock tables
notiz fuer mich selbst:
mysql_backup nutzt myqsldump, um ein backup von mysql zu machen. auf manchen meiner server gibts dann die fehlermeldung:
mysqldump: Got error: 1556: You can't use locks with log tables. when doing LOCK TABLES
als loesung einfach die entsprechende zeile (mysqldump) im script suchen und das hinzufuegen:
--skip-lock-tables
owncloud external storage support
seit version 4 bietet owncloud die moeglichkeit, “externes” storage einzubinden. d.h. man kann bereits vorhandene “cloudspeicher” einbinden und ueber das owncloud interface darauf zugreifen. irgendie soll das wohl mit dropbox und gdrive usw funktionieren, aber ich habs erstmal mit ftp probiert. hilfe findet man auf der seite “Custom Mount Configuration“. da steht auch nix von dropbox etc. geschrieben.
um einen ftp server einzubinden muss man die datei config/mount.php anlegen. in meinem falle mit folgendem inhalt (benutzernamen etc. sind natuerlich anzupassen);
array(
'ich'=>array(
'/ich/files/mountpoint/'=>array('class'=>'OC_Filestorage_FTP',
'options'=>array('host'=>'www.ftphost.tld',
'user'=>'ftpUserName',
'password'=>'ftpPassWord'))
)
)
);
?>
diese mounts kann man wahlweise fuer bestimmte user und gruppen oder auch fuer alle anlegen. details siehe link oben.
ich habe auf dem besagten ftp ca. 3000 bilder liegen. owncloud “scannt” diese natuerlich erstmal. dabei werden die dateisystem objekte erstmal mit name, datum, hashwert etc in der tabelle fscache abgelegt. wenn es sich um bilder handelt und man mit der integrierten gallery durch diese browst, legt owncloud auch noch thumbnails im userverzeichnis (unterverzeichnis “gallery”) unterhalb des “datadirectory” an.
zu weiteren spielereien bin ich noch nicht gekommen… ich finds aber irgendwie suboptimal, dass owncloud fuer meine 3000 bilder auf dem remoteserver 22672 (!) einzelne logins gemacht hat.
problem mit umlauten nach owncloud update
.. von version 3 auf 4… sieht scheisse aus:

der kalender sah aehnlich aus. und so kriegt man es weg, ohne an der collation der datenbank rumschrauben zu muessen. was jetzt sinnvoller ist, mag ich fuer mich gerade nicht entscheiden. so hab ich wenigstens die datenbank so, wie sie bei der installation mal angelegt wurde.
UPDATE calendar_objects SET summary = REPLACE(summary, 'ä', 'ä');
UPDATE calendar_objects SET summary = REPLACE(summary, 'ü', 'ü');
UPDATE calendar_objects SET summary = REPLACE(summary, 'ö', 'ö');
UPDATE calendar_objects SET summary = REPLACE(summary, 'Ãœ', 'Ü');
UPDATE calendar_objects SET summary = REPLACE(summary, 'Ä', 'Ä');
UPDATE calendar_objects SET summary = REPLACE(summary, 'Ãœ', 'Ö');
UPDATE calendar_objects SET summary = REPLACE(summary, 'ß', 'ß');
UPDATE calendar_objects SET calendardata = REPLACE(calendardata, 'ä', 'ä');
UPDATE calendar_objects SET calendardata = REPLACE(calendardata, 'ü', 'ü');
UPDATE calendar_objects SET calendardata = REPLACE(calendardata, 'ö', 'ö');
UPDATE calendar_objects SET calendardata = REPLACE(calendardata, 'Ãœ', 'Ü');
UPDATE calendar_objects SET calendardata = REPLACE(calendardata, 'Ä', 'Ä');
UPDATE calendar_objects SET calendardata = REPLACE(calendardata, 'Ãœ', 'Ö');
UPDATE calendar_objects SET calendardata = REPLACE(calendardata, 'ß', 'ß');
UPDATE contacts_cards SET carddata = REPLACE(carddata, 'ä', 'ä');
UPDATE contacts_cards SET carddata = REPLACE(carddata, 'ü', 'ü');
UPDATE contacts_cards SET carddata = REPLACE(carddata, 'ö', 'ö');
UPDATE contacts_cards SET carddata = REPLACE(carddata, 'Ãœ', 'Ü');
UPDATE contacts_cards SET carddata = REPLACE(carddata, 'Ä', 'Ä');
UPDATE contacts_cards SET carddata = REPLACE(carddata, 'Ãœ', 'Ö');
UPDATE contacts_cards SET carddata = REPLACE(carddata, 'ß', 'ß');
UPDATE contacts_cards SET fullname = REPLACE(fullname, 'ä', 'ä');
UPDATE contacts_cards SET fullname = REPLACE(fullname, 'ü', 'ü');
UPDATE contacts_cards SET fullname = REPLACE(fullname, 'ö', 'ö');
UPDATE contacts_cards SET fullname = REPLACE(fullname, 'Ãœ', 'Ü');
UPDATE contacts_cards SET fullname = REPLACE(fullname, 'Ä', 'Ä');
UPDATE contacts_cards SET fullname = REPLACE(fullname, 'Ãœ', 'Ö');
UPDATE contacts_cards SET fullname = REPLACE(fullname, 'ß', 'ß');
