Tag: debian
debian 10 (buster): ipv6 deaktivieren
um ipv6 auf einem debian buster system zu deaktivieren, muss man folgendes machen:
am ende der datei /etc/sysctl.conf eine zeile einfuegen:
echo 'net.ipv6.conf.all.disable_ipv6 = 1' >> /etc/sysctl.conf
und die config neu einlesen mit
sysctl -p
wenn man das nur auf einem statt auf allen netzwerk interfaces machen will, muss man das “all” durch das entsprechende interface ersetzen:
echo 'net.ipv6.conf.ens18.disable_ipv6 = 1' >> /etc/sysctl.conf
statt in die eine allgemeingueltige sysctl.conf rein zu schreiben, kann man auch eine gesonderte datei anlegen:
echo 'net.ipv6.conf.all.disable_ipv6 = 1' > /etc/sysctl.d/90-disable-ipv6.conf
diese muss man beim neu einlesen aber auch explizit angeben:
sysctl -p -f /etc/sysctl.d/90-disable-ipv6.conf
nach upgrade von debian stretch auf buster: Could not open logfile /var/log/unbound/unbound.log: Permission denied
ich benutze unbound als resolver fuer meine mailserver. nach dem upgrade von stretch auf buster wurde nichts mehr ins logfile unbound.log unter /var/log/unbound/ geschrieben.
die berechtigungen passen alle, owner und group sind “unbound” und schreiben duerfen beide auch.
wie sich rausgestellt hat, ist apparmor hier das problem. um das schreiben in die logfiles wieder zu erlauben, muss eine zeile in die datei /etc/apparmor.d/local/usr.sbin.unbound eingefuegt werden:
echo "/var/log/unbound/unbound.log rw," >> /etc/apparmor.d/local/usr.sbin.unbound
danach die config datei neu laden
apparmor_parser -r /etc/apparmor.d/usr.sbin.unbound
und unbound neu starten.
service unbound restart
that’s it.
proxmox: remove dead ceph node (osd/mon) after removing cluster node
after removing a pve cluster node that was also a ceph osd and monitor node i realised that i forgot to remove the ceph stuff before removing the node from the cluster. there is no possibility to remove it with the pve gui, so i have to do it on the command line.
to delete it from the ceph crush map:
ceph osd crush rm nodenametoremove
to remove the monitor:
ceph mon remove nodenametoremove
the edit the file /etc/ceph/ceph.conf and remove the complete section for the node.
then edit the file /etc/ceph/storage.conf and remove the ip address of the dead monitor node. this step can also be done via the gui.
proxmox: eine partition als osd nutzen
gleich vorneweg: nicht offiziell von proxmox unterstuetzt, aber (fuer mich) funktionieren tuts. 😉
fuer meine aktuelle “spielwiesen-evaluierung” habe ich als boot platte eine 500 GB ssd gekauft. da das betriebsystem und swap nur wenige gigabytes benoetigen, moechte den restlichen platz als OSD fuer ceph verwenden. proxmox unterstuetzt von haus aus nur kompletten festplatten als OSD. mit ein paar tricks kann man das aber trotzdem eintueten. dafuer muessen ein paar vorraussetzungen eingehalten und die folgenden schritte ausgefuehrt werden.
1. als grundlage habe ich ein debian stretch installiert. dabei waehlt man am besten den modus “expert install” aus, da man nur in diesem den typ der partition table der festplatte setzen kann. der installer macht standardmaessig eine MBR patrition table, aber wir brauchen zwingend eine des typs GPT!
2. das debian system samt proxmox und ceph installieren (siehe proxmox wiki)
3. danach muss die OSD partition wie folgt angelegt und praepariert werden:
als erstes setzen wir ein paar variablen… der partition typecode “is designating a Ceph data disk”
PTYPE_UUID=4fbd7e29-9d25-41b8-afd0-062c0ceff05d
die festplatte, die verwendet werden soll:
disk=/dev/sda
die nuemmer der partition ist die naechste freie nummer:
part=4
und eine zufaellige UUID wird benoetigt, um die neue OSD zu identifizieren:
(wenns nicht funktioniert, vorher noch das paket “uuid-runtime” installieren)
OSD_UUID=`uuidgen -r`
wenn all diese variablen gesetzt sind, kann mit dem sgdisk kommando die neue partition angelegt werden:
sgdisk --largest-new=$part --change-name="${part}:ceph" --partition-guid=${part}:$OSD_UUID --typecode=${part}:$PTYPE_UUID $disk
der output koennte so aussehen:
Setting name!
partNum is 3
REALLY setting name!
Warning: The kernel is still using the old partition table.
The new table will be used at the next reboot or after you
run partprobe(8) or kpartx(8)
The operation has completed successfully.
um die proxmox boardmittel nutzen zu koennen, muss man ein bischen in einem perl script rumpfuschen… und zwar das: /usr/share/perl5/PVE/API2/Ceph.pm
vorher bitte eine sicherungskopie anlegen, damit man die originale datei im anschluss wiederherstellen kann. (funktioniert mit pve 5.2)
suche in der datei nach diesem string:
$devname =~ s|/dev/||;
…und kommentiere diese und die folgenden zeilen bis zu dieser aus:
my $devpath = $diskinfo->{devpath};
dann fuege diese zeile darunter ein:
my $devpath = $devname;
jetzt suche nach
my $cmd = ['ceph-disk', 'prepare', '--zap-disk',
…und entferne am ende das argument “–zap-disk”, so dass die zeile so aussieht:
my $cmd = ['ceph-disk', 'prepare',
dann kann man endlich die OSD erstellen:
pveceph createosd /dev/sda4 --bluestore=0
(wenn die fehlermeldung “not a valid block device” kommt, ist noch ein reboot notwendig, damit der kernel die oben abgeaenderte partition table frisst.)
ich habe hier bluestore auf 0 gesetzt, da es bei mir nicht funktioniert hatte. (ich bin mir garnicht sicher, ob man bluestore ueberhaupt mit einer partition verwenden kann… vermutlich eher nicht.) so wird der herkoemmliche typ “filestore genommen und die partition mit xfs formatiert.
der output koennte so aussehen:
create OSD on /dev/sda4 (xfs)
meta-data=/dev/sda4 isize=2048 agcount=4, agsize=29150209 blks
= sectsz=4096 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=0, rmapbt=0, reflink=0
data = bsize=4096 blocks=116600833, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=56934, version=2
= sectsz=4096 sunit=1 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
und zum schluss noch die OSD aktivieren, wodurch die partition gemountet und der zugehoerige OSD daemon gestartet wird
ceph-disk activate /dev/sda4
und schon ist die partiton unter proxmox als OSD verfuegbar. in der proxmox oberflaeche wird die ganze festplatte als OSD angezeigt, was mich aber nicht weiter stoert 😉
proxmox spontane reboots oder alle festplatten “verloren”
in einem proxmox/ceph cluster mit insgesamt sieben nodes sind vier identische nodes nur für den ceph storage zustaendig. alles supermicro x8dtl-3f mit ssds und 10gbit nics.
irgendwann… ich weiss nicht genau wann… aber auf jeden fall nach dem update auf debian stretch und pve5 hatten diese vier server problemchen. erstmal sah es so aus, als ob es mehrere verschiedene probleme sind.
1. in einem zeitraum von 1 bis 7 tage booteten die server spontan und ohne erkenntlichen grund. keine eintraege im syslog und nichts im bios/ipmi eventlog zu sehen.
2. weniger haeufig kam es vor, dass ein node zwar noch “online” war, aber alle seine festplatten “verloren” hat. seh dann auf dem bildshirm so aus:
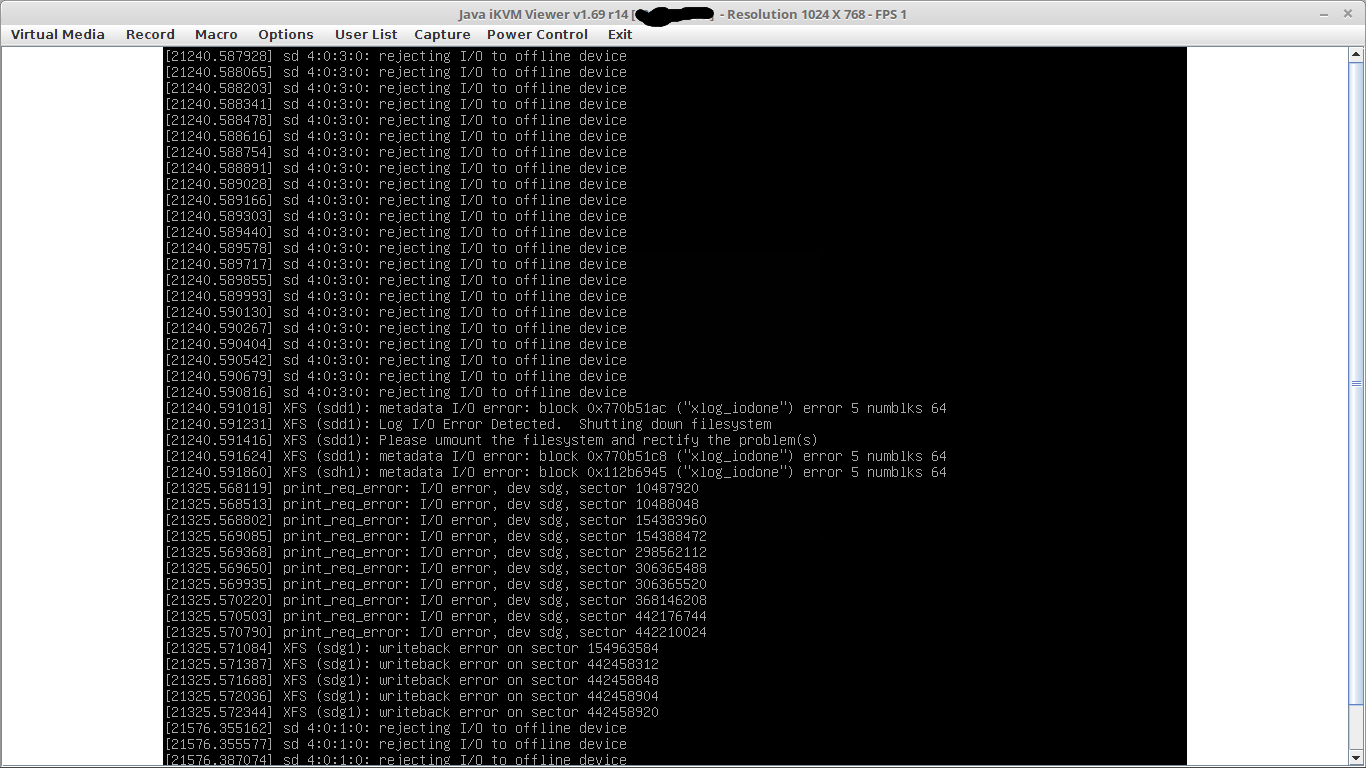
3. die onboard netzwerkkarten haben rumgezickt, was im logfile dann so aussah:

das hat sich dann im sekundentakt wiederholt
4. selten bekam ich meldungen wie diese auf den schirm:
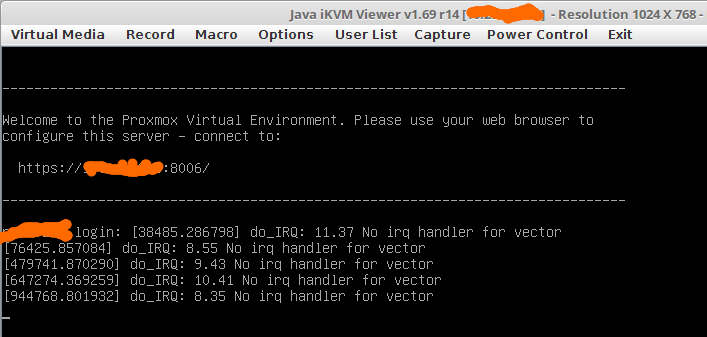
wie sich aber rausstellte, war das genau das ausschlaggebende! falls noch was im syslog zu sehen war (eher garnicht ausser bei dem nic flapping), dann war auch immer so eine meldung unmittelbar davor zu sehen.
nach ein wenig googlen kam heraus, dass der “irqbalanced” fuer diese meldungen verantwortlich ist. der irqbalanced kann im laufenden betrieb irq’s bei bedarf auf eine andere cpu mappen. wenn man google nach diesem ding fragt, bekommt man viele aussagen. von “braucht man nicht, weil aktuelle kernels das von alleine koennen” bis “sehr wichtig bei hoher last fuer performanceoptimierungen”.
ich hab dann kurzerhand in der datei /etc/default/irqbalance den parameter “IRQBALANCE_ONESHOT=YES” gesetzt. in der beschreibung dazu steht: “after starting, wait for a minute, then look at the interrupt load and balance it once; after balancing exit and do not change it again.”
….und was soll ich sagen. seit vier wochen habe ich nun ruhe und die server lauifen durch 🙂
fuer eine genaua analyse und warum das seit wann auftritt… puh.. da fehlt mir die zeit. ich hab mich lange genug damit beschaeftigt und nun laufen die kisten wieder rund.
steinalter proftpd auf debian etch
mir wurde die ehre zuteil, auf einem uralten server mit debian etch proftpd mit mysql support fuer die userdb zu konfigurieren. nur leider wollte das ums verrecken nicht funktionieren. beim login versuch kam im logfile immer nur:
FTP session requested from unknown class
lange gesucht, aber doch noch gefunden…
When you get a message saying “FTP session requested from unknown class” on Debian Etch 4.0 (ProFTPD Version 1.3.0) and you are trying to use MySQL authentication, this is probably due to the
LoadModule mod_sql_postgres.c
in /etc/proftpd/modules.conf file, which line should be commented out. I see this as a bug in the proftpd package, since I have NOT installed the proftpd-pgsql package, so this line should not be present, and also, at least it shouldn’t affect the work of the proftpd-mysql package, which is successfully installed.
was eine alte hundekacke. auskommentiert und gut.
linux: altes mainboard, grosse platten, software raid
irgendwie bin ich in sachen hardware nicht mehr up to date. ein nich tmehr ganz neues, schnuckeliges supermicro 1he gehaeuse mit einem brauchbaren dual core xeon stand noch rum. hmm… zwei grosse platten rein und daraus einen backup server gebaut. gesagt getan… aber waere zu schoen, wenn mal alles auf anhieb klappen wuerde.
erstmal musste ich lernen, dass aeltere bios’se mit 4TB platten nicht koennen. knapp 2TB wurden vom bios erkannt. aber nach kurzer recherche war klar, dass man nur die partition zum booten entsprechend klein halten und am anfang platzieren muss. der rest der grossen platte wird dann vom betriebssystem erkannt. (zumindest bei einem linux)
lektion zwei war, dass bei der nutzung von grossen platten, gpt und grub am anfang der platte eine kleine partition vom typ EF02 (BIOS boot partition) vorhanden sein muss. irgendwas soll das mit uefi zu tun haben, was ich aber garnicht habe. verstanden habe ich das alles nicht… aber egal. einfach machen.
die partitionierung bzw das anlegen dieser einen partition musste ich mit einer knoppix cd machen, da auf der debian netinst keine passenden programme drauf sind, um partition auf einer platte mit GPT zu erstellen. (ja, mit sicherheit ist da sowas drauf, aber ich hab nix mir bekanntes gefunden.)
also husch auf beiden platten identische partitionen vom typ EF02 angelegt. dann mit der debian netinst cd die restlichen platten partitioniert, MD devices angelegt, konfiguriert und installiert. und dann geschahen komische dinge…. nach der installation wollte die kiste nicht booten. da kam so ein kauderwelsch:
mdadm: Devices UUID-7a140585:a601a93a:a6265560:0120df65 and
UUID-7a140585:a601a93a:a6265560:0120df65 have the same name: /dev/md/0
mdadm: Duplicate MD device names in conf file were found.
Gave up waiting for root device. Common problems:
- Boot args (cat /proc/cmdline)
- Check rootdelay= (did the system wait long enough?)
- Check root= (did the system wait for the right device?)
- Missing modules (cat /proc/modules; ls /dev)
ALERT! /dev/disk/by-uuid/c5bf7b81-f808-4bf7-b554-f7bc2d6c0479 does not exist
Dropping to shell!
die loesung dazu gabs dann im debianforum. aus der datei /etc/mdadm/mdadm.conf muss man den doppelten eintrag raus loeschen. welcher der richtige ist… keine ahnung. bei mir wars praktischerweise der erste 😉
mit “exit” kommt man dann aus der busybox raus und die kiste startet. damits beim naechsten boot noch klappt, noch das ausfuehren:
update-initramfs -vu
ich hab dann gleich noch den grub auch auf die zweite platte installiert. fuer den fall, dass /dev/sda ausfaellt und man von /dev/sdb booten muss.
dpkg-reconfigure -plow grub-pc
apt: signatures couldn’t be verified
damits hier auch mal geschrieben stehtn und ich mich nicht jedes mal durch fremde seiten wuehlen muss, wenns wieder passiert 😉
als beispiel…. wenn man ein “fremdes” repository in die “/etc/apt/sources.list” einbaut, wie z.b. das von opsview…
[..]
# Opsview packages
deb http://downloads.opsview.com/opsview-core/latest/apt squeeze main
[..]
…dann passiert es natuerlich auch mal, dass bei einem apt-get die signaturen der packages nicht geprueft werden koennen:
W: GPG error: http://downloads.opsview.com squeeze Release:
The following signatures couldn't be verified because the
public key is not available: NO_PUBKEY 327C70CD0FC6984B
und das bekommt man in den griff, in dem man einfach den passenden key runterlaedt..
gpg --keyserver pgpkeys.mit.edu --recv-key 327C70CD0FC6984B
..und importiert
gpg -a --export 327C70CD0FC6984B | apt-key add -
und feddich 🙂
debian: in welchem paket steckt datei xy
schon oft gebraucht.. .jetzt hier notiert. wie kann man rausfinden, durch welches debian paket eine bestimmte datei installiert wurde? das geht ganz einfach so:
dpkg -S /usr/bin/strings
der output:
binutils: /usr/bin/strings
amavisd tmp verzeichnis permission denied
eine frische installation von amavis und clamav werkelt bei debian wheezy nicht out of the box. diese berechtigungsprobleme werden im mail.og ausgegeben:
Dec 21 13:27:09 mxxx amavis[20283]: (20283-01) (!)run_av (ClamAV-clamd) FAILED - unexpected , output="/var/lib/amavis/tmp/amavis-20131221T132753-20283-SD4gQJVU/parts: lstat() failed: Permission denied. ERROR\n"
Dec 21 13:27:09 mxxx amavis[20283]: (20283-01) (!)ClamAV-clamd av-scanner FAILED: CODE(0x1c8e750) unexpected , output="/var/lib/amavis/tmp/amavis-20131221T132753-20283-SD4gQJVU/parts: lstat() failed: Permission denied. ERROR\n" at (eval 111) line 899.
Dec 21 13:27:09 mxxx amavis[20283]: (20283-01) (!)WARN: all primary virus scanners failed, considering backups
grund ist – wer haette das ahnen koennen – fehlende berechtigung. da das verbiegen dieser im dateisystem bei updates oft nach hinten losgeht, muss man die gruppenberechtigung der user anpassen. ich habs mit der grossen keule gemacht 😉
usermod -a -G clamav amavis
usermod -a -G clamav clamav
usermod -a -G amavis clamav
usermod -a -G amavis amavis
danach die dienste neu starten und gut.
service clamav-daemon restart
service amavis restart
service postfix restart
