Author: sd


proxmox spontane reboots oder alle festplatten “verloren”
in einem proxmox/ceph cluster mit insgesamt sieben nodes sind vier identische nodes nur für den ceph storage zustaendig. alles supermicro x8dtl-3f mit ssds und 10gbit nics.
irgendwann… ich weiss nicht genau wann… aber auf jeden fall nach dem update auf debian stretch und pve5 hatten diese vier server problemchen. erstmal sah es so aus, als ob es mehrere verschiedene probleme sind.
1. in einem zeitraum von 1 bis 7 tage booteten die server spontan und ohne erkenntlichen grund. keine eintraege im syslog und nichts im bios/ipmi eventlog zu sehen.
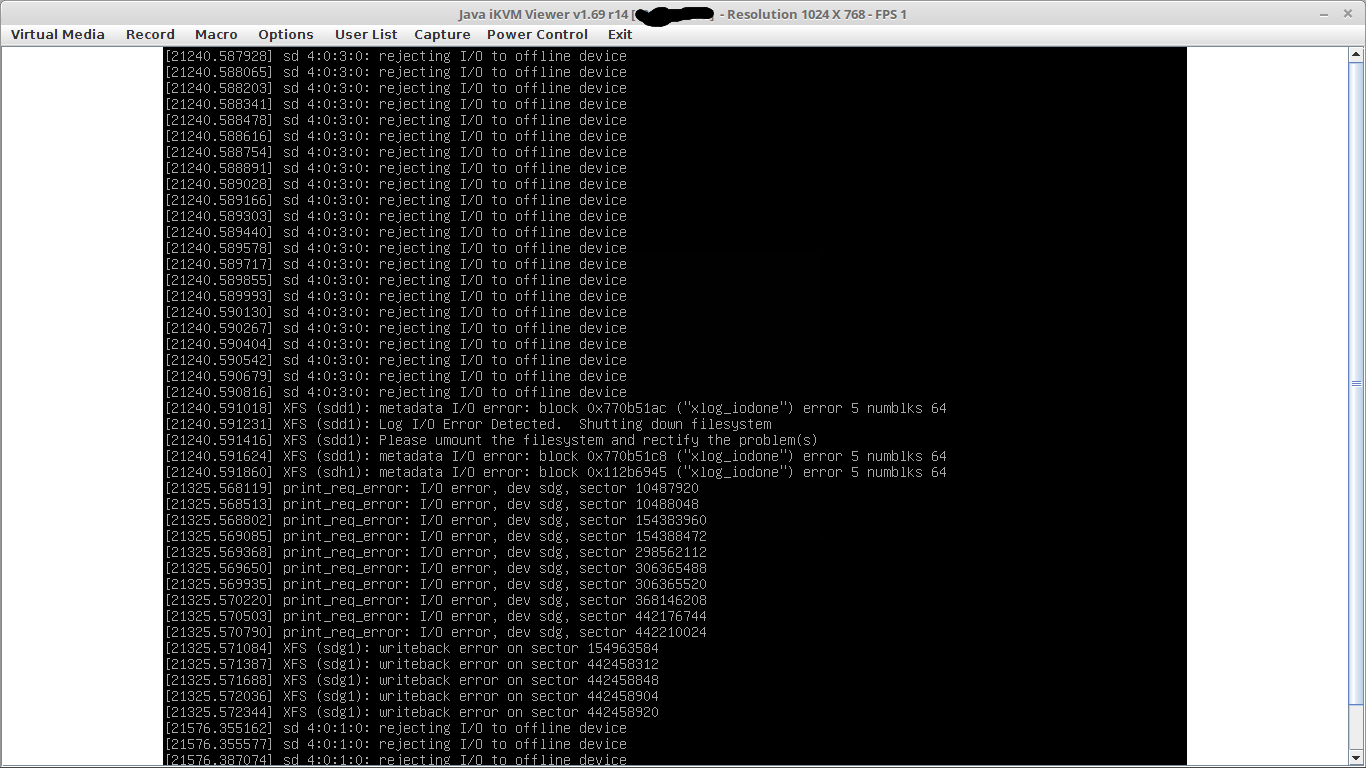
2. weniger haeufig kam es vor, dass ein node zwar noch “online” war, aber alle seine festplatten “verloren” hat. seh dann auf dem bildshirm so aus:
3. die onboard netzwerkkarten haben rumgezickt, was im logfile dann so aussah:

das hat sich dann im sekundentakt wiederholt
4. selten bekam ich meldungen wie diese auf den schirm:
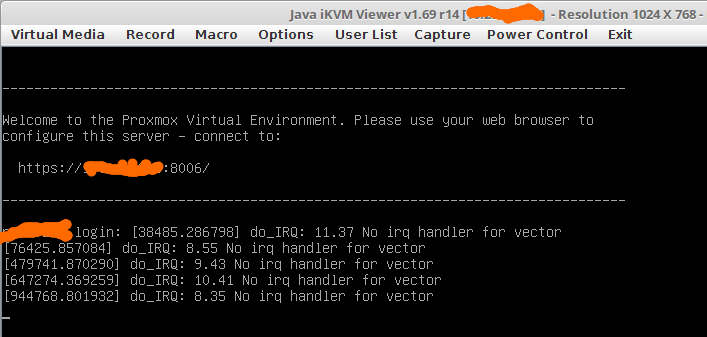
wie sich aber rausstellte, war das genau das ausschlaggebende! falls noch was im syslog zu sehen war (eher garnicht ausser bei dem nic flapping), dann war auch immer so eine meldung unmittelbar davor zu sehen.
nach ein wenig googlen kam heraus, dass der “irqbalanced” fuer diese meldungen verantwortlich ist. der irqbalanced kann im laufenden betrieb irq’s bei bedarf auf eine andere cpu mappen. wenn man google nach diesem ding fragt, bekommt man viele aussagen. von “braucht man nicht, weil aktuelle kernels das von alleine koennen” bis “sehr wichtig bei hoher last fuer performanceoptimierungen”.
ich hab dann kurzerhand in der datei /etc/default/irqbalance den parameter “IRQBALANCE_ONESHOT=YES” gesetzt. in der beschreibung dazu steht: “after starting, wait for a minute, then look at the interrupt load and balance it once; after balancing exit and do not change it again.”
….und was soll ich sagen. seit vier wochen habe ich nun ruhe und die server lauifen durch 🙂
fuer eine genaua analyse und warum das seit wann auftritt… puh.. da fehlt mir die zeit. ich hab mich lange genug damit beschaeftigt und nun laufen die kisten wieder rund.

…egal, wie sie sich entscheiden
auf irgendeiner webseite wollte ich ein PDF runterladen. dann kam diese fehlermeldung:
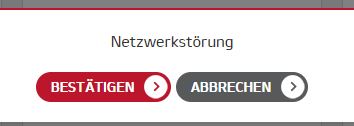
und egal, welchen knopf man drueckt… man kam immer wieder zur downloadseite zurueck. warum macht man sowas?
reihenfolge der kalender in nextcloud bzw. der default kalender
eine alte owncloud installation habe ich “aus gruenden” endlich mal auf nextcloud aktualisiert. soweit war alles fein, aber in meinen sehr umfangreichen kalendern waren wohl ein paar syntaktische probleme enthalten. weil ich das bei der menge an eintraegen niemals einfach und schnell rausbekommen haette, waehlt ich eine holzhammer mehode. einmal exportieren, kalender loeschen, neu anlegen und wieder importieren.
bis dahin war der kalender mit dem namen “default” auch mein wirklicher default kalender und bei nutzung der webgui war dieser bei neu erstellten eintraegen auch vorausgewaehlt. nach meiner o.g. aktion war er es leider nicht mehr. jedes mal beim erstellen eines eintrages den passenden kalender auswaehlen war aber auch keine loesung. also gesucht und was gefunden. der beschrieben bug ist schon seit zwei jahren gemeldet… nur erledigt hats scheinbar noch niemand. da ich kein programmierer bin bin ich eher auf die workarounds angewiesen. diesen mag ich hier kurz beschreiben….
erstmal schauen, was da bei meinen kalendern so drin steht:
SELECT id, displayname, uri, calendarorder FROM oc_calendars WHERE principaluri LIKE '%MYUSERNAME;

da in dem feld “calendarorder” ueberall NULL drin steht, wirds erstmal gesetzt (auf wert “1”):
UPDATE oc_calendars SET calendarorder=1 WHERE principaluri LIKE '%MYUSERNAME%';
…um dann danach den richtigen kalender (“default” mit id 773) in der reihenfolge (calendarorder) eins hoeher (0 statt 1) zu setzen:
UPDATE oc_calendars SET calendarorder=0 WHERE principaluri LIKE '%MYUSERNAME%' AND id=773;
nach einem reload der webgui ist nun wieder alles paletti 🙂
bots aussperren per iptables
irgendwann haben mal irgendwelche drecks bots einen uralten webserver lahm gelegt.
an die robots.txt haben sie sich nicht gehalten und eigentlich sollte die seite von keiner suchmaschine gecrawled werden. also aussperren nach diesem muster:
for i in `cat /var/log/apache/*.log | grep YandexBot|cut -d" " -f1|sort|uniq`; do iptables -A INPUT -s $i -j DROP; done
das parst die apache logs, filtert nach dem entsprechenden bot, und sperrt die genutzten ips.
quick and dirty 😉
ceph blinkenlights
zu dem beitrag mit dem proxmox/ceph cluster gibts noch ein schickes video:
und das im dunkeln anzusehen… hach… das kann jeden nerd dazu bringen, ewigkeiten davor zu stehen und einfach nur stur auf das geblinke zu starren. so wie bei einem lagerfeuer.
ceph recovery io
hab ichs schonmal gesagt? ich liebe ceph. und bei solchen datenraten beim recovery … boah…
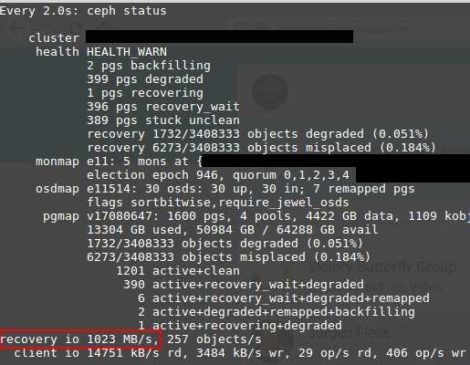
(nein, das ist nicht von meinem “spiel cluster” auf intel NUC basis mit usb3 platten 😉 )
proxmox/ceph cluster in miniatur
ich lehne mich jetzt mal aus dem fenster uns behaupte, dass ich eines der “kleinsten” proxmox/ceph cluster habe, die je so gebaut wurden. klein im sinne von physischen abmessungen. die hardware ausstattung ist zwar nicht so der high performance kram, aber fuer die groesse recht ansehnlich.
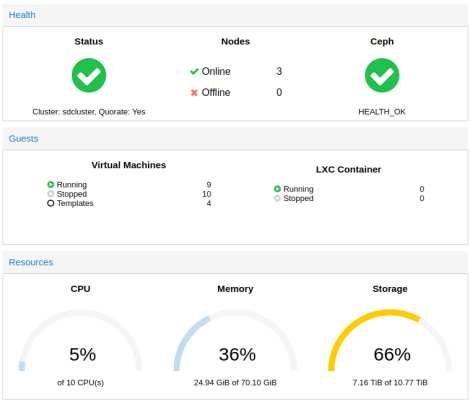
3x intel NUC mit 9x 2,5 zoll usb 3.0 platten und ein synology slim nas. da eckdaten:
10 CPU cores
70 GB ram
6 TB ceph storage (brutto)
4 TB nfs storage (synology)
fuer das, was man so zuhause rumexperimentieren muss, langt mir das (fuers erste) 😀
das ganze sieht dann so aus: (erste ausbaustufe)

der hdd platz im ceph war mir bald zu klein, so dass ich noch drei weitere platten dran gehaengt hab:

da aber die platten nun dicht an dicht gepackt waren, musste ich mir was einfallen lassen, da die einfach zu warm wurden. dazu hab ich baumarkt ein paar alu profile gekauft, zersaegt und mit sekundenkleber zusammengebastelt.

was dann am ende so aussieht:

so ist dann etwas luft zwischen den platten und das alu kann vielleicht ein bischen waerme ableiten. wenns nicht reicht, kann ich noch ein oder zwei luefter dahinter haengen.
