Tag: linux
ceph und festplattencontroller
man muss ja selbst seine erfahrungen machen mit ceph & co…. die leute von proxmox schreiben in ihren forumsbeitraegen auch immer, dass man seine hardware vor dem betrieb testen soll.
bei einer erweiterung meines ceph storages hab ich gedacht: oh… da ist ein adaptec raid controller drin. mit viel cache und ner backup batterie. und den kann man auch ohne raid betreiben, wenn man den in seinem bios in den HBA mode stellt. gesagt – getan. funktionierte auch erstmal. aber wenn man mal genauer hin schaut, ist die apply/commit latenz bei einigen OSDs um ein vielfaches hoeher, als bei den anderen. hier nur ein beispiel bild, bei dem die werte noch “relativ” niedrig waren. (die node in der mitte des screenshots)
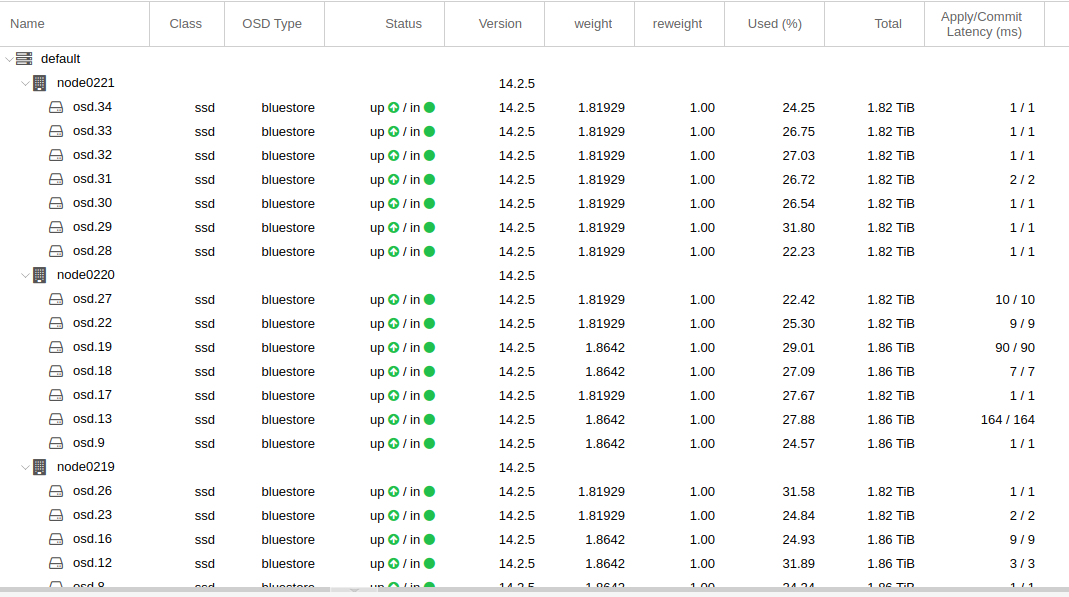
tja – mein gedanke mit “der adaptec controller kanns doch bestimmt besser, als die schnoeden onboard sata dinger” … war dann wohl nix. die ceph doku schreibt “Disk controllers also have a significant impact on write throughput. Carefully, consider your selection of disk controllers to ensure that they do not create a performance bottleneck.”
also controller rausgerissen und die ganze sata kabelage ausgetauscht und die onboard intel controller benutzt…. und siehe da.. die latenz ist “normal”:
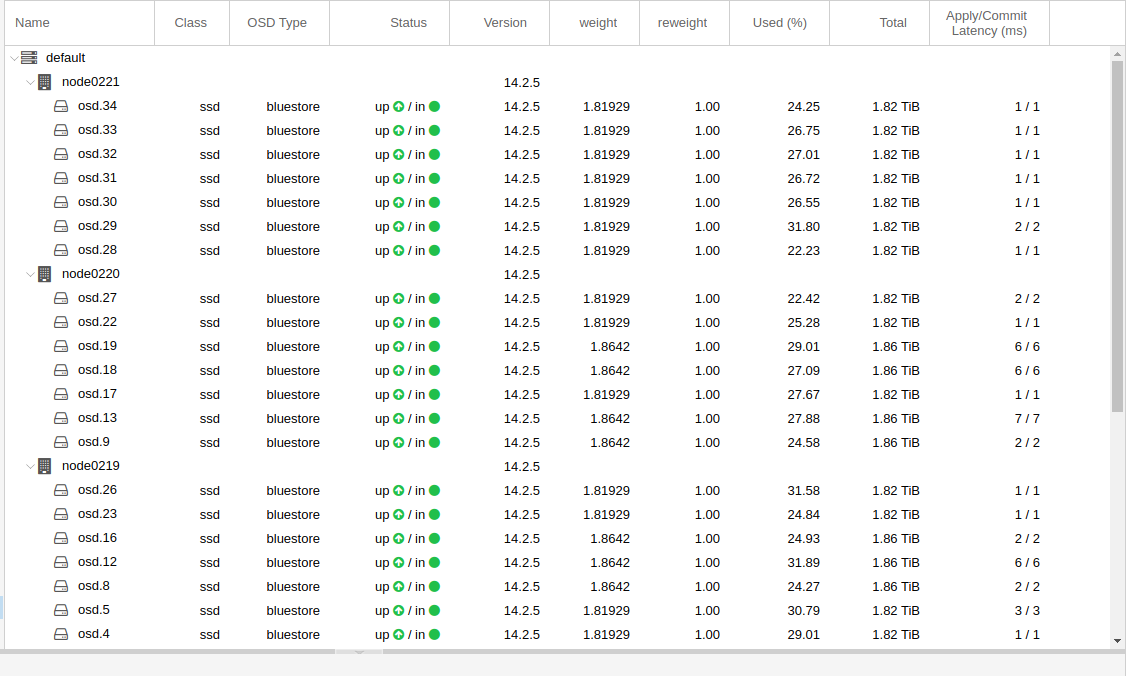
kann man auch wunderschoen beim “IO delay” (in blau) erkennen:

auch die proxmox doku schreibt dazu:
“Avoid RAID
As Ceph handles data object redundancy and multiple parallel writes to disks (OSDs) on its own, using a RAID controller normally doesn’t improve performance or availability. On the contrary, Ceph is designed to handle whole disks on it’s own, without any abstraction in between. RAID controller are not designed for the Ceph use case and may complicate things and sometimes even reduce performance, as their write and caching algorithms may interfere with the ones from Ceph.”
jaja… ist ja gut. wie immer erstmal vorher lesen. aber am besten lernt man natuerlich aus den eigenen fehlern 😉
linux: die seriennummer einer festplatte rausfinden
da gibt es mehrere moeglichkeiten. ein paar davon hier gelistet.
command:
udevadm info --query=all --name=/dev/sda | grep ID_SERIAL_SHORT
output:
E: ID_SERIAL_SHORT=1828E1487BE33
command:
hdparm -I /dev/sda | grep 'Serial\ Number'
output:
Serial Number: 1828E1487BE33
command:
lshw -class disk|grep serial
output:
serial: 1828E1487BE33
command:
smartctl -i /dev/sda | grep Serial
output:
Serial Number: 1828E1487BE33
command:
lsblk --nodeps -o name,serial|grep sda
output:
sda 1828E1487BE33
command:
ls -al /dev/disk/by-id/|grep -e sda$|grep -v wwn
output:
lrwxrwxrwx 1 root root 9 Nov 13 05:23 ata-CT500MX500SSD1_1828E1487BE33 -> ../../sda
citrix: error cannot connect to 0.0.0.2
ich musste unter linux (mint) mit der citrix workspace app arbeiten. beim laden der ica-datei kam der fehler “error cannot connect to 0.0.0.2 appname”. hier die loesung… irgendwo beim googlen gefunden… weiss nur nicht mehr wo:
cd /opt/Citrix/ICAClient/keystore/
sudo rm -r cacerts
sudo ln -s /etc/ssl/certs cacerts
debian 10 (buster): ipv6 deaktivieren
um ipv6 auf einem debian buster system zu deaktivieren, muss man folgendes machen:
am ende der datei /etc/sysctl.conf eine zeile einfuegen:
echo 'net.ipv6.conf.all.disable_ipv6 = 1' >> /etc/sysctl.conf
und die config neu einlesen mit
sysctl -p
wenn man das nur auf einem statt auf allen netzwerk interfaces machen will, muss man das “all” durch das entsprechende interface ersetzen:
echo 'net.ipv6.conf.ens18.disable_ipv6 = 1' >> /etc/sysctl.conf
statt in die eine allgemeingueltige sysctl.conf rein zu schreiben, kann man auch eine gesonderte datei anlegen:
echo 'net.ipv6.conf.all.disable_ipv6 = 1' > /etc/sysctl.d/90-disable-ipv6.conf
diese muss man beim neu einlesen aber auch explizit angeben:
sysctl -p -f /etc/sysctl.d/90-disable-ipv6.conf
nach upgrade von debian stretch auf buster: Could not open logfile /var/log/unbound/unbound.log: Permission denied
ich benutze unbound als resolver fuer meine mailserver. nach dem upgrade von stretch auf buster wurde nichts mehr ins logfile unbound.log unter /var/log/unbound/ geschrieben.
die berechtigungen passen alle, owner und group sind “unbound” und schreiben duerfen beide auch.
wie sich rausgestellt hat, ist apparmor hier das problem. um das schreiben in die logfiles wieder zu erlauben, muss eine zeile in die datei /etc/apparmor.d/local/usr.sbin.unbound eingefuegt werden:
echo "/var/log/unbound/unbound.log rw," >> /etc/apparmor.d/local/usr.sbin.unbound
danach die config datei neu laden
apparmor_parser -r /etc/apparmor.d/usr.sbin.unbound
und unbound neu starten.
service unbound restart
that’s it.
ceph filestore osd in bluestore umwandeln
um problemen beim umstieg von proxmox 5 auf 6 aus dem weg zu gehen, wollte ich alle “alten” OSDs von filestore auf bluestore “umwandeln”. ausserdem solls ja noch ein quentchen perforemance bringen. es gab auch mindestens noch einen grund, der mir aber entfallen ist.
auf jeden fall hatte ich fuer diesen zweck irgendwann und irgendwo mal ein scriptchen gefunden. das schaut so aus:
ID=$1
echo "ceph osd out $ID"
ceph osd out $ID
# wait to start ceph remapping all things
sleep 10
while ! ceph health | grep HEALTH_OK ; do sleep 10 ; done
echo "systemctl stop ceph-osd@$ID.service"
systemctl stop ceph-osd@$ID.service
sleep 10
DEVICE=`mount | grep /var/lib/ceph/osd/ceph-$ID| cut -f1 -d"1"`
umount /var/lib/ceph/osd/ceph-$ID
echo "ceph-disk zap $DEVICE" ----> /dev/sdd1 das geht net
ceph-disk zap $DEVICE
ceph osd destroy $ID --yes-i-really-mean-it
echo "ceph-disk prepare --bluestore $DEVICE --osd-id $ID"
ceph-disk prepare --bluestore $DEVICE --osd-id $ID
#wait some seconds for metatdata visible
sleep 10;
ceph osd metadata $ID
ceph -s
echo "wait for cluster ok"
while ! ceph health | grep HEALTH_OK ; do echo -e "."; sleep 10 ; done
ceph -s
echo " proceed with next"
das ding als ausfuehrbares script abspeichern und der nummer der umzuwandelnden OSD als uebergebenen parameter starten. natuerlich kann man das auch in einer kleinen for schleife fuer alle OSDs machen. die alte filestore OSD wird aus dem cluster rausgenommen und als neue bluestore OSD wieder eingehaengt. natuerlich muss die ganze disk dann wieder syncen. ist also besser, wenn man eine nach der anderen macht.
phpmyadmin mit fail2ban absichern
seit phpmyadmin 4.8 gibt es endlich eine logging funktion fuer die fehlgeschlagenen logins. diese kann man dann wunderbar per fail2ban auswerten. frueher war das eher eine wurschtelei mit customized apache logs oder gar aenderungen an den installierten phpmyadmin dateien (welche nach einem update wieder futsch waren). standardmaessig ist diese logging funktion auch enabled und schreibt die fehlgeschlagenen logins ins php error logfile oder syslog. der parameter in der config.inc.php heisst $cfg[‘AuthLog’] und hat den wert “auto”. phpmyadmin entscheidet dann selbststaendig, ob es ins php error log oder syslog schreibt. in meinem falle machte es das ins php error log. wenn nicht, kann man den wert entsprechend setzen.
hier ist das die datei /var/www/webxxxx/logs/priv/php_errors.log. die eintraege im log haben dieses format:
[19-May-2019 21:07:49 Europe/Berlin] user denied: phpmyadmin (mysql-denied) from 46.246.65.167
zuerst muss man einen entsprechenden filter fuer fail2ban konfigurieren. dazu einfach die datei /etc/fail2ban/filter.d/phpmyadmin.conf mit diesem inhalt anlegen:
[Definition]
denied = mysql-denied|allow-denied|root-denied|empty-denied
failregex = ^.*(%(denied)s).* from $
ignoreregex =
beim debuggen seiner eigenen regex kann die seite debuggex.com sehr hilfreich sein. testen kann man seinen selbst erstellten filter mit diesem befehl:
fail2ban-regex /var/www/webxxxx/logs/priv/php_errors.log /etc/fail2ban/filter.d/phpmyadmin.conf
im ergebnis sollten dann irgendwie so in der art aussehen:
[...]
Lines: 31 lines, 0 ignored, 10 matched, 21 missed
[...]
bei “matched” sollte eine entsprechende anzahl groesser 0 auftauchen. wenn dem so ist, braucht man noch eine “jail” konfiguration fuer phpmyadmin. dazu die datei
/etc/fail2ban/jail.d/phpmyadmin.conf mit diesem inhalt anlegen:
[phpmyadmin]
enabled = true
port = http,https
filter = phpmyadmin
logpath = /var/www/webxxxx/logs/priv/php_errors.log
einmal neu laden ….
service fail2ban reload
… und einfach mal ein paar fehlerhafte loginversuche ausloesen. im php error log sieht das so aus:
[24-May-2019 07:51:45 Europe/Berlin] user denied: dasdsadsadas (empty-denied) from 87.xxx.xx.xx
[24-May-2019 07:51:46 Europe/Berlin] user denied: dasdsadsadas (empty-denied) from 87.xxx.xx.xx
[24-May-2019 07:51:47 Europe/Berlin] user denied: dasdsadsadas (empty-denied) from 87.xxx.xx.xx
[24-May-2019 07:51:48 Europe/Berlin] user denied: dasdsadsadas (empty-denied) from 87.xxx.xx.xx
[24-May-2019 07:51:49 Europe/Berlin] user denied: dasdsadsadas (empty-denied) from 87.xxx.xx.xx
und korrespondierend im fail2ban logfile:
/var/log/fail2ban.log
2019-05-24 07:51:45,862 fail2ban.filter [1144]: INFO [phpmyadmin] Found 87.xxx.xx.xx
2019-05-24 07:51:46,936 fail2ban.filter [1144]: INFO [phpmyadmin] Found 87.xxx.xx.xx
2019-05-24 07:51:47,952 fail2ban.filter [1144]: INFO [phpmyadmin] Found 87.xxx.xx.xx
2019-05-24 07:51:48,832 fail2ban.filter [1144]: INFO [phpmyadmin] Found 87.xxx.xx.xx
2019-05-24 07:51:49,592 fail2ban.filter [1144]: INFO [phpmyadmin] Found 87.xxx.xx.xx
2019-05-24 07:51:50,303 fail2ban.actions [1144]: NOTICE [phpmyadmin] Ban 87.xxx.xx.xx
2019-05-24 08:01:51,276 fail2ban.actions [1144]: NOTICE [phpmyadmin] Unban 87.xxx.xx.xx
bei dem jail greifen hier die fail2ban standard werte einer debian 9 installation. nach 5 fehlerhaften logins von einer IP wird diese fuer 10 minuten per iptables geblockt.
that’s it.
bind pi-hole-FTL to certain ip addresses
to bind pihole-FTL to certain ip adresses, you need to add parameters to dnsmasq. if not exist, create a file /etc/dnsmasq.d/99-my-settings.conf with the following settings:
listen-address=127.0.0.1,10.10.60.9,10.10.61.9,10.10.66.9
bind-interfaces
restart pihole-FTL and verify the result
root@ph:~# netstat -nltup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
[...]
tcp 0 0 10.10.61.9:80 0.0.0.0:* LISTEN 762/lighttpd
tcp 0 0 127.0.0.1:53 0.0.0.0:* LISTEN 1752/pihole-FTL
tcp 0 0 10.10.61.9:53 0.0.0.0:* LISTEN 1752/pihole-FTL
tcp 0 0 10.10.60.9:53 0.0.0.0:* LISTEN 1752/pihole-FTL
tcp 0 0 10.10.66.9:53 0.0.0.0:* LISTEN 1752/pihole-FTL
[...]
linux : jnlp dateien ausfuehren
in zusammenhang mit >diesem< artikel sei hier noch beschrieben, was man machen muss, falls "das eine etwas" fehlt auf dem system, auf dem man die datei ausfuehren moechte.
sudo apt-get install icedtea-netx
und dann einfach den befehl “javaws” mit der entsprechenden file ausfuehren:
javaws filename.jnlp
netgear GS108Ev3 firmware upgrade
fuer den heimgebrauch ist diese serie von netgear ja durchaus OK. selbst wenn man mit VLANs arbeitet, kann man da grundlegende konfigurationen machen und es funktioniert auch meistens. der preis der geraete entschaedigt fuer eventuelle unannehmlichkeiten.
ich wollte mal schauen, ob ich in der config auch einen syslog server eintragen kann… nix gefunden. also mal ein firmware update machen… vielleicht ruesten die sowas ja nach. (das schon vorneweg: nein)
also habe ich das geraet in den firmware-update-modus versetzt und versucht, die neue firmware ueber den browser hochzuladen. das hochladen ging auch… nur dann ist nix mehr passiert. also einmal neu gestartet… und da war das geraet nicht mehr unter der eingestellten ip erreichbar, sondern unter der default ip laut werkseinstellungen (192.168.0.239). firmware update hat trotzdem nicht funktioniert. aber das geraet war nun permanent im update modus.
dann habe ich versucht, tatsaechlich auf werkseinstellungen zurueck zu setzen… keine aenderung. immer noch im update modus.
auf irgendeiner netgear KB seite habe ich dann gelesen, dass es jemand mit allen moeglichen browsern probiert hat, aber nur mit chrome unter windows erfolg hatte. ich hatte auch schon alle moeglichen browser durch… unter anderem auch chromium unter linux. was solls… bevor ich das geraet wegschmeisse, probiere ich es auch mal mit windows und chrome aus…. und siehe da! firmware upgrade hat funktioniert! (anders als das ruecksetzen auf werkseinstelungen – meine einstellungen waren danach noch alle da.)
ich erwarte ja echt nicht viel von einem managebaren switch fuer 35 euro… zumal er ja schon vlans kann. aber man sollte wenigstens mit irgendeinem browser ein firmware update machen koennen und nicht extra dafuer ein windows vorhalten muessen.
